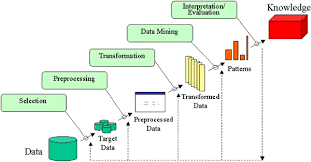
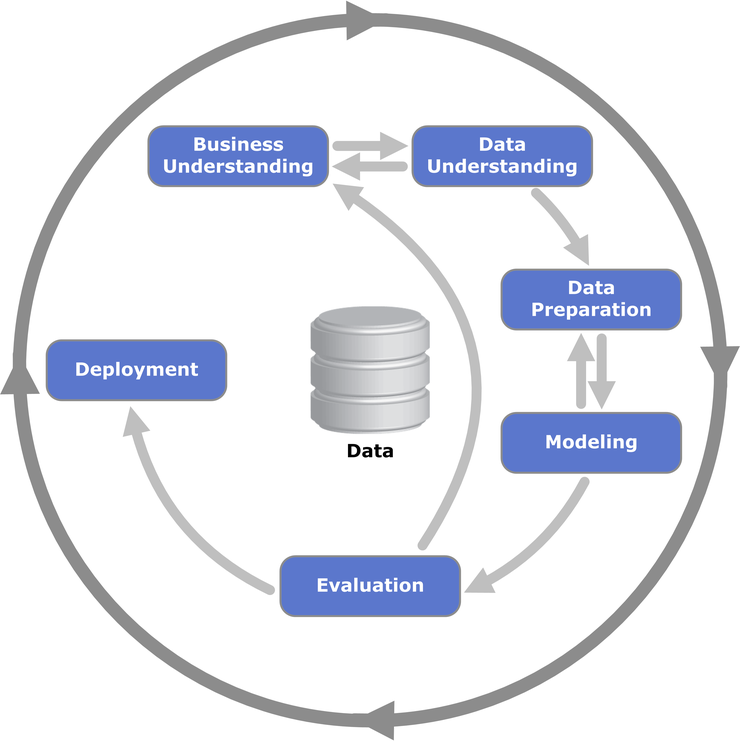
빅데이터 관점에서 아키텍처(Architecture)란 무엇일까요?
그리고 아키택트(Architect)는 무엇을 해야할까요?
이를 위해서는 먼저 용어에 대한 정확한 이해가 필요하겠지요?
// (그전에 잠깐 !!! 왜 빅데이터가 중요한지 알고계시죠? ^^
// 바로 지난 포스팅에서도 언급되었지만 4차 산업혁명의 핵심 기반이 빅데이터이기 때문입니다.)
그래서 먼저 구글에서 조사해 보겠습니다.
구글에서 아키텍처 라고 검색하면 아래와 같이 나옵니다.
-
컴퓨터를 기능면에서 본 구성 방식. 기억 장치의 번지 방식, 입출력 장치의 구성 방식 등을 가리킴. 일반적으로 같은 아키텍처의 컴퓨터에는 소프트웨어의 호환성(互換性)이 있음.
음...무슨 무슨 방식 이라는 용어가 눈에 들어오네요.
우리가 원하는 것은 빅데이터, 그리고 IT시스템과 관련된 아키텍처의 정의를 원하고 있으므로
그 아래 위키 백과에 있는 시스템 아키텍처에 대한 정의가 더 적합 할 것 같습니다.
위키 백과에서는 시스템 아키텍처(System Architecture)를 '시스템이 어떻게 작동하는지를 설명하는 프레임워크' 라고 정의하고 있습니다.
그리고 시스템 목적을 달성하기 위한 각 컴포넌트가 무엇이며, 어떻게 상효작용하는지 등을 설명하는 것이라고합니다.
여기서 보니 프레임워크, 컴포넌트, 상호작용 이라는 용어가 눈에 들어옵니다. 그리고 결국 시스템 아키텍처란 시스템을 설명하기 위한 무엇이네요.
위키에서 프레임워크를 계속해서 찾아보니 '복잡한 문제를 해결하거나 서술하는 데 사용되는 '기본 개념 구조'라고 되어있습니다.
컴포넌트는 다른 말로 구성요소 이니, 결국 아키텍처란 '시스템을 잘 설명하기위해 구성요소와 구조, 관계 등을 설명하는 자료' 라고 할 수 있겠습니다.
이해가 되시는지요?
그래서 구글에서 아키텍처라고 검색하고 이미지를 누르면 아래와 같이 대부분이 순서도와 같은 블럭과 선으로 그려진 이미지들이 보이네요.
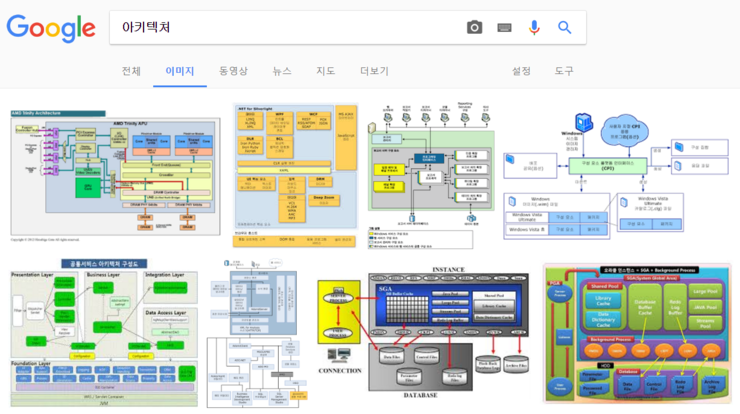
그래서 아키텍처를 Box-Line Diagram 이라고 부르기도 한답니다.^^
사실 아키텍처는 지금으로부터 약 10년전에 유행했었습니다.
바로 엔터프라이즈 아키텍처 라는 이름으로 유행했었죠.
우리가 배운 내용으로 무슨 내용일지 유추해 볼까요?
엔터프라이즈는 기업이고 아키텍처는 위에서 말한 것 처럼 설명을 하기 위한 구성요소, 구조 이니...
풀어서 설명하면 기업을 설명하기위해 정리된 구성요소와 구조, 관계를 말합니다. 이런 것은 대부분 박스와 선으로 그려진 이미지로 정리될 수 있고요.
좀더 깔끔하게 정리된 위키 백과의 내용을 보면 아래와 같습니다.
엔터프라이즈 아키텍처(Enterprise Architecture; EA)는 조직의 프로세스 및 정보 시스템 및 부서의 구조와 기능을 포괄적이고 정확한 방법으로 기술하는 방법이고, 이것을 통해 조직이 전략적 목표에 따라 행동하도록 방향을 제시하는 것이다. 정보기술(IT)와 관련이 깊지만, 사업 최적화도 관련이 깊고, 사업구조, 성과관리, 조직구조 아키텍처 등으로 불린다.
자세히 보니 기업에서 수립되는 전략을 슬로건이나 경영 방침/목표로 삼고 추진하는 것도 좋지만 엔터프라이즈 아키텍처로 만들어서 이미지로 구체화 하면 더욱 이해하기 쉬울 것 같다는 생각이 들었습니다.
엔터프라이즈 아키텍처(EA)는 다시 서브 아키텍처로 구성되는데 주로 4가지로 구성됩니다.
즉, 비즈니스 아키텍처(BA: Business Architecture), 어플리케이션 아키텍처(AA: Application Architecture), 데이터 아키텍처(DA: Data Architecture), 기술 아키텍처(TA: Technical Architecture) 로 구성됩니다. (EA 이야기는 시간이되면 따로 하겠습니다. 이분야도 엄청나게 넓은 분야여서 설명에 많은 시간이 필요할 것 같습니다. 아! 그리고 4가지 뿐만 아니라 정책, 원칙, 표준, 보안 등 다른 요소를 추가하여 EA를 구성하는 기업도 있습니다. 이는 기업의 업종과 특성에 따라 추가될 수 있습니다. 이런 요소가 포함된 것을 엔터프라이즈 거버넌스라고도 합니다.)
그래도 우리가 배운 지식을 이용해서 짧게 설명하고 넘어가자면 비즈니스 아키텍처는 기업의 비즈니스를 잘 설명하기 위해 구성요소를 정의하고 구성요소간의 관계를 정리한 자료이고, 어플리케이션 아키텍처는 이러한 기업의 비즈니스 활용을 위한 주요 IT시스템의 구성 내용과 관계를 정리한 것이라 할 수 있으며, 데이터 아키텍처는 기업 전체의 데이터가 어떻게 구성되고 어떻게 관계/운영되는지를 정리한 자료가 될 것 같습니다. 그리고 기술 아키텍처는 이러한 시스템들을 구축/운영하기 위한 하드웨어/기술의 구성요소와 요소간의 관계를 정리한 자료라고 할 수 있겠습니다. 구체적인 자료로 보면 프로세스 멥, 기능 멥, 데이터 (개념/논리/물리)모델, 서버/Network 구성도가 될 것 같습니다.
보통 단위/단일 시스템의 아키텍처에도 동일하게 적용하여 시스템 구축 전에 아키텍처를 설계하고 설계에 따라 시스템을 구축하게 됩니다. (물론 국내에서는 주로 대형 프로젝트가 아니면 시간과 비용을 아끼고자 이러한 아키텍처 설계 부분이 무시되거나 축소되는 경향이 많습니다. - 체계적이지 못한 것이지요)
이렇게 해서 대략적인 아키텍처, 엔터프라이즈 아키텍처 그리고 그와 관련된 BA, AA, DA, TA 등에 대한 용어를 익히게 되었습니다.
기본부터 시작하다보니 중요한 것을 빼먹었는데요.....
시스템 아키텍처는 왜 필요할까요?
좀더 쉽게 (공부했으니까..^^) 시스템을 잘 설명하기 위한 구성/구조/관계를 정리한 자료가 왜 필요할까요?
잠시, 생각해보시죠.
....
생각하고계시죠 ? ! ......
....
생각나셨나요? 네, 결국 시스템을 잘 구축하고 활용/관리하기 위해서 필요하며, 또다른 중요한 이유는 다른 관계자(사용자, 개발자 등)와 소통하기 위한 자료/Tool로서 필요합니다. 여기서 조금 더 들어가면, 시스템을 잘 구축하고 활용/관리 한다는 의미는 결국 시스템 구축시, 운영시, 변경시 아키텍처가 있으면 효율적으로(싸고/빠르고/품질좋은 시스템을) 구축할 수 있다는 것이고, 운영시 장애에 효과적으로 대처할 수 있으며, 시스템의 확대/변경 필요시에도 효율적으로 대응할 수 있음을 의미합니다.
많이 오기는 했는데요 ^^, 제가 앞으로 말씀드릴 내용은 바로 빅데이터 아키턱처에 대한 이야기 입니다.
아키텍처는 이제 이해 되셨죠...빅데이터는 그냥 간단하게 큰 데이터라고 생각하시면 됩니다.
초기에 빅데이터를 정의하고 특징을 말핼때 3V 라고해서
데이터의 크기(Volume), 데이터의 속도(Velocity), 데이터의 다양성(variety)을 강조 했습니다.
요즘은 여기에 가치(Value)를 추가하여 4V라고 합니다.
다시말하면 3가지의 특징을 가지는 데이터를 빅데이터라고 말할 수 있습니다.
단일시스템에서 보관할 수 없을 정도 크기(Volume)의 데이터, 실시간으로 생성,저장,시각화 되야하는 데이터,
그리고, 포멧이 정해진 DBMS의 테이블이 아니라, 이미지, 택스트파일, 비디오/오디오 파일 등 비정형의 다양한 데이터까지포함하는 다양성(Variety)을 가지는 데이터를 말합니다.
이러한 빅데이터를 수집/저장/처리/분석하기위한 아키텍처는 어떻게 구성해야하는지를 앞으로 이야기해보도록 하겠습니다.
빅데이터가 확대 생산되면서 이에 대한 저장/관리/처리/활용이 더욱 중요하게 되었고 목적에 따라 새로운 아키텍처 패턴이 필요하게 되었으며, 최근에적용이 확대되면서 더욱 중요해지고 있기 때문이죠.
이후에는 비즈니스 요건과 이에 따른 아키텍처 패턴에 대해서 차근차근 알아보겠습니다.
감사합니다.
'빅데이터_Big Data ' 카테고리의 다른 글
| 빅데이터와 SNS시대의 소셜 경험 전략 (0) | 2017.02.06 |
|---|---|
| EDW와 빅데이터 아키텍처 (0) | 2017.01.20 |
| 데이터 분석 방법론 (KDD, SEMMA, CRISP-DM) (0) | 2017.01.08 |
| 5-1. 고객분석의 목적 (0) | 2017.01.08 |
| 4 - 고객 프로파일링(Customer Profiling) - 데이터 분석 프레임 관점 (0) | 2017.01.07 |