Port Forwarding 방법입니다.
집에있는 와이파이 공유기를 이용해서 외부 인터넷에서오는 요청을 처리할 수 있는 환경을 만드는 방법입니다.
특히, 2개의 공유기를 사용하는 경우입니다.
SKB에 전화해서 물어봐도 설명을 잘 못해주었고 잘 이해 못하는 상담원도 계셔서 한 다섯 번 정도 통화했던 것 같습니다.
결국 인터넷에서 관련된 설명 링크를 찾았다고 보내주어 참고하였습니다. 큰 도움은 안됬어요.
그 만큼 복잡하고 이해하기 어려웠습니다.
제가 고생을 했기 때문에 다른 분들께서는 고생 안하시고 도움이 되었으면 좋겠습니다.
지금부터 하나하나 설명해 드립니다. 따라해보세요.
참 아래 글을 보시는 방법은, 먼저 설명을 적어 놓았으니 간단히 읽어보시고, 그 바로 아래에 관련 이미지를 추가 했어요, 순서대로 보시면서 따라하시면 됩니다.
전체적인 연결구조는 아래와 같습니다
인터넷 -》 공유기1(SKB) -》 공유기2(iptime) -》 PC
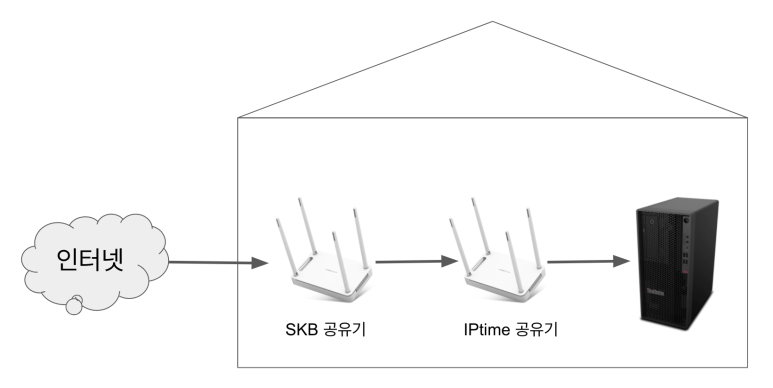
전체 구조
먼저 SKB 공유기를 설정합니다.
192.168.25.1 로 접속하면 로그인 창이 나옵니다.
id는 admin, 암호는 공유기 뒷면 MAC 주소+"_admin" 을 입력합니다.
뒷면에 MAC 주소가 안보이는 경우(초기 설정하신 경우) 휴대폰을 통해 접속해서 와이파이MAC 주소를 알아낼 수 있습니다. (아래 링크를 참고하세요)
https://bigdatamaster.tistory.com/119
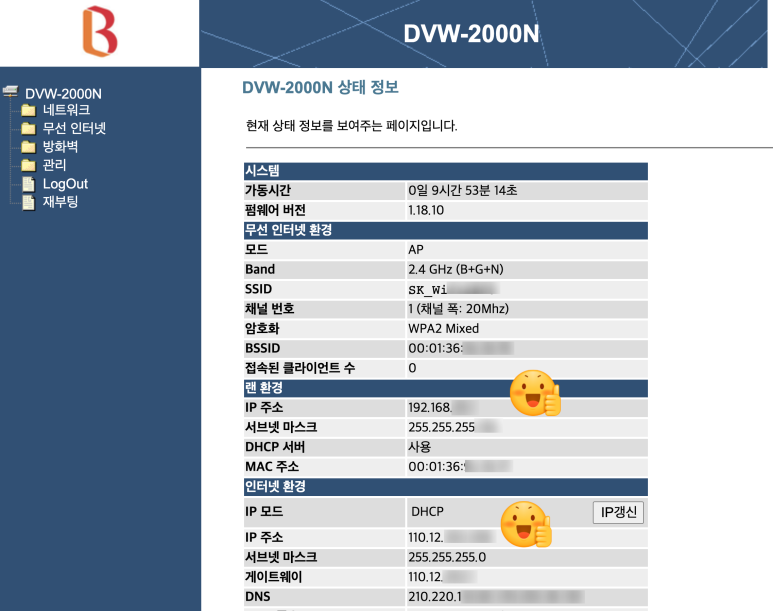
로그인하고 나면 아래의 화면이 보입니다.
여기서는 인터넷 환경에 있는 IP 주소를 기억해 둡니다. 여기서는 110.12. 으로 나와있는 부분 입니다.
이 번호가 인터넷을통해서 다른 장비가 접근할 때 사용하는 IP번호 입니다.
나중에 설정을 완로한 후 테스트 할 때 필요하니 별도로 적어 놓거나 저장해 놓으시기 바랍니다.
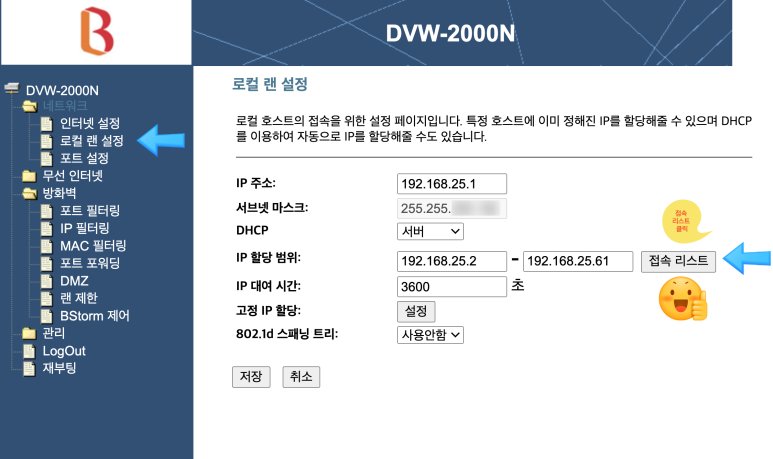
좌측 메뉴 중에서 로컬 랜 설정 부분을 클릭합니다.
그러면 아래의 이미지 오른쪽 화면이 나오는데 이때 접속 리스트를 클릭합니다.
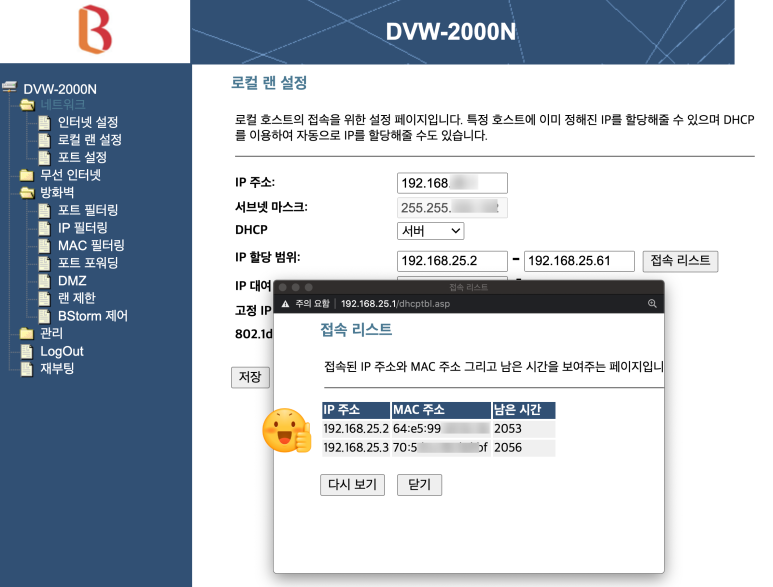
위에서 접속리스트를 클릭하면 접속 리스트 창이 팝업됩니다.
여기에 나오는 IP 주소를 적어 둡니다. 이 IP 주소가 바로 두번째 공유기인 ip time 공유기의 내부 주소 입니다.
아래 화면에서 메뉴 방화벽 -> 포트 포워딩을 클릭합니다.
오른 쪽에 포트 포워딩 리스트가 나오며, 제일 하단에 새로운 포트 포워딩을 추가 할 수 있습니다.
로컬 IP 주소는 이전 페이지인 접속 리스트에 나왔던 숫자를 입력합니다.
포트 범위에 외부에서 들어오는 포트중 어떤 포트 번호를 넘길지 적어 주고 설명을 입력후 추가 버튼을 누릅니다.
버튼을 누르고 잠시 있으면 리스트에 추가되어 보여집니다.
(옵션)정상적으로 보이면 왼쪽 메뉴에 있는 재부팅을 클릭/ 실행합니다. 1~2분 기다리면 재부팅이 완료됩니다.
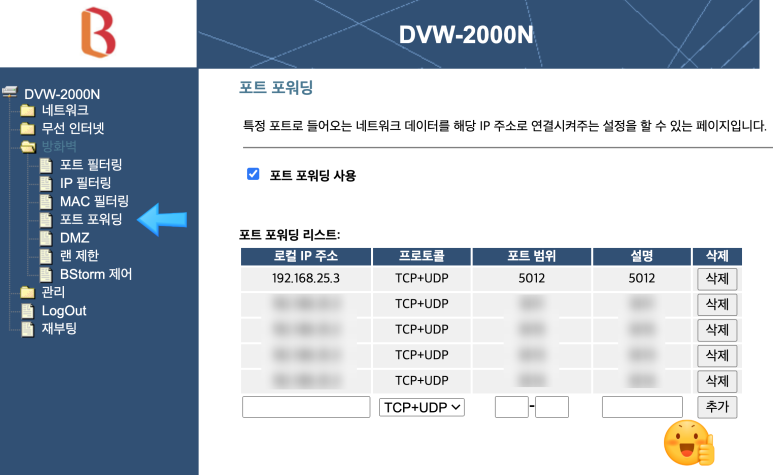
지금까지 작업한 것은 인터넷에서 들어온 요청을 공유기1번에서 공유기2번으로 넘기는 작업을 한 것입니다.
힘내세요!.. 이미 반 이상 완료되었습니다.

이제부터 두번째 ip time 공유기에 설정을 시작합니다.
192.168.0.1 에 접속하면 iptime 로그인 화면이 나옵니다.
초기 설정할때 입력했던 id/password를 이용하여 로그인하고
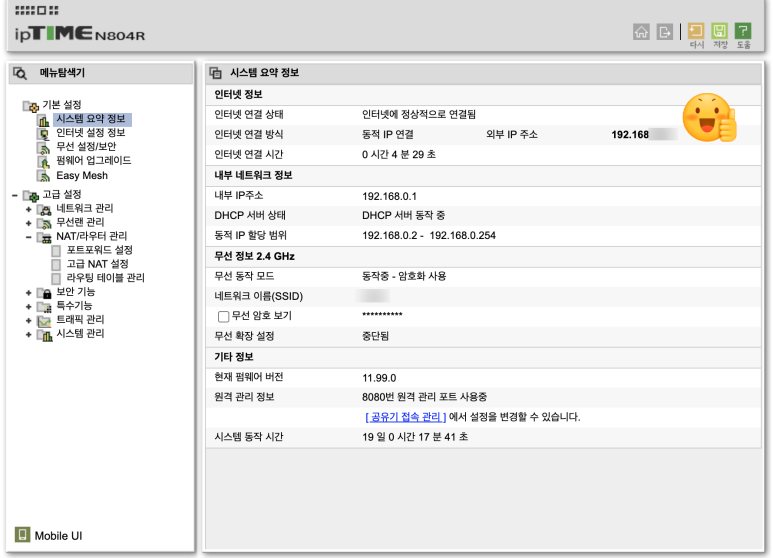
관리도구와 설정화면 둘이 보이는 화면이 나올 때 관리도구를 클릭하면 아래와 같은 화면이 보입니다.
오른쪽 위에 보이는 외부IP주소가 공유기1에서 설정한 정보와 같은지 확인합니다.
(주의 !!! 만약에 외부IP 주소가 다른 번호라면 첫번째 공유기에서 다른 곳으로 포워딩 하도록 설정된 것입니다. 따라서 두번째 공유기에서 보이는 번호를 이용해서 다시 첫번째 공유기의 내용을 설정해 줘야 합니다.)
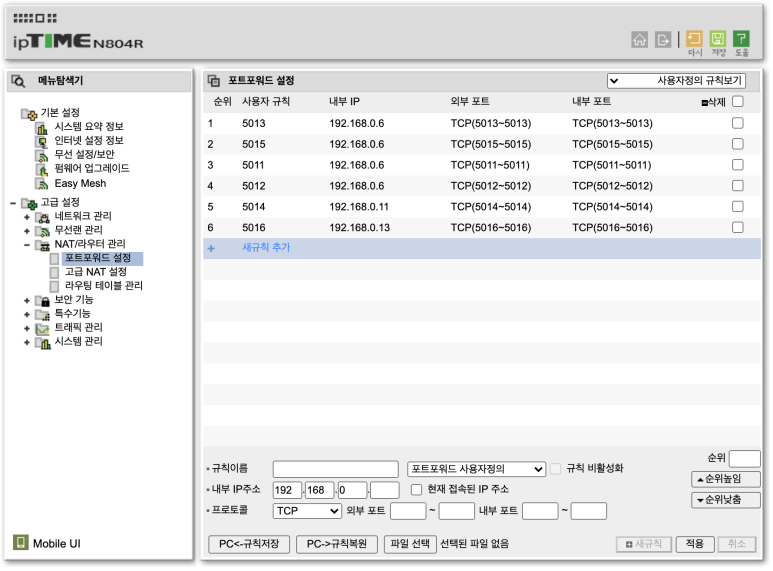
왼쪽 메뉴에서 고급설정 -> NAT/라우터 관리 -> 포트 포워드 설정을 클릭하면 왼쪽 화면이 보입니다.
왼쪽 아래를 보면 새로운 포트포워드를 등록하는 부분이 있습니다.
내용을 입력 합니다.
현재 접속된 IP주소의 왼쪽에있는 체크박스를 클릭하면 자동으로 현재 접속/사용중인 장비의 IP가 자동으로 등록됩니다.
특히 외부포트와 내부포트를 잘 설정해야 합니다.
외부포트는 공유기에서 받는(외부에서 들어올 수 있도록 열어 놓은) 포트 입니다.
내부포트는 내부IP주소의 장비(PC/ 노트북 등)에서 받아들이는 포트입니다.
(저는 혼동을 막기 위해 그냥 같은 포트 번호를 사용했습니다.)
내용 작성후 적용을 클릭합니다.
위의 리스트에 새로 추가된 설정이 보이면 오른쪽 상단에 있는 저장 버튼을 누릅니다.
지금까지 설명을 따라서 진행하셨으면 이제 설정이 잘 되었는지 확인해봅니다.
최종 오픈을 위한 장비에서 아래의 페이지에 접속한 다음,
위에서 오픈한 포트번호을 이용해서 오픈되어있는지 아닌지를 확인할 수 있습니다.
쉽게 따라하셔서 한번에 잘 설정되셨기를 바랍니다.
설정이 잘되었는지 확인하는 방법은 아래링크에서 설명 드립니다.
https://bigdatamaster.tistory.com/90
포트 포워딩 설정 확인방법 ㅡ SKBroadband, IPtime 공유기 사용 환경 설정 확인 방법
이전 포스팅에서는 포트포워딩 설정 방법에 대해서 설명드렸습니다. 포트 포워딩 SKBroadband, IPtime 공유기 사용 환경 설정 방법 port forwarding 방법입니다. https://bigdatamaster.tistory.com/89 이번에..
bigdatamaster.tistory.com
https://bigdatamaster.tistory.com/92
무료 웹서버구축 : 집에서 무료로 개인 웹 페이지 호스팅하는 방법
집에서 인터넷 접속 서비스를 가입하고 있고(KT, SKB, LG 등), PC가 있으면 무료로 개인 웹 페이지 호스팅을 할 수 있습니다. 인터넷 공유기에서 포트 포워딩을 하고 PC에서 제공할 웹 페이지를 호스
bigdatamaster.tistory.com
감사합니다.
아래에 있는 공감 클릭해 주시면 감사하겠습니다..
잘 안되시면 댓글 주세요. 다시 한번 감사합니다.
추가 정보입니다.
1. SKB에서는(KT미확인) 공유기 접속 갯수를 재한하지 않는다고 합니다. 따라서 다양한 구성이 가능합니다.
2. 포워딩이 됬다가 안됬다가 하는 경우가 있습니다.
이는 공유기 재부팅시 사설IP가 유동IP로 재설정되기 때문에 다른 공유기의 IP번호가 바뀌게 됩니다. 이런 경우 잘되던 포워딩이 추가 포워딩 설정을 저장하고 나서 갑자기 안되는 경우가 발생합니다.
3. 시스템 포트는 사용에 주의하세요.
포트번호 1번부터 1024번까지는 시스템에서 사용하는 포트 번호 입니다. 따라서 포트 포워딩에 사용시 주의해야합니다. 안전하게 2000번 이상의 포트번호를 사용해 보세요.
감사합니다.~
아래 댓글도 참고하세요 ~
'빅데이터_Big Data ' 카테고리의 다른 글
| Flume 기본 개념 및 기초 (0) | 2017.07.01 |
|---|---|
| 5 - 고객 프로파일링(Customer Profiling) - 기술 구현 관점 (0) | 2017.03.16 |
| 데이터 분석 방법론 (2) - 예시포함 (CRISP-DM) (2) | 2017.02.25 |
| 빅데이터와 SNS시대의 소셜 경험 전략 (0) | 2017.02.06 |
| EDW와 빅데이터 아키텍처 (0) | 2017.01.20 |