크롬 앱 스토어에서는 ChatGPT를 활용하는 다양한 플러그인 앱들이 올라와 있는데요, 그 중에서 실용적이고 많이 사용되고 있는 앱인 WebChatGPT를 소개 시켜 드리겠습니다. 이글을 읽고나면 WebChatGPT가 무엇인지, 어떤 효과가 있는지, 어떻게 사용하는지 등을 아실 수 있습니다. 이를 통해서 검색이나 ChatGPT를 사용할 때 좀더 쉽고 빠르게 원하는 정보를 얻으실 수 있습니다. 동영상 설명 자료는 여기를 참고해주세요.
무엇인가? : WebChatGPT란?
WebChatGPT는 ChatGPT를 사용하여 검색 결과와 ChatGPT의 결과를 향상 시키는 크롬 브라우저의 플러그인 앱 입니다. 그래서 크롬 앱 스토어로부터 앱을 설치할 수 있습니다. 이 앱의 목적은 인터넷 검색 결과를 활용하여 ChatGPT에 제공 할 질문(프롬프트)을 만들어주는 앱 입니다. 그래서 2가지 방법으로 사용될 수 있는데, 크롬에서 검색시에 사용될 수 있고 ChatGPT에서 채팅 시에 사용될 수 있습니다.
어떤 것을 할 수 있나? : 어떤 기능 이 있는가?
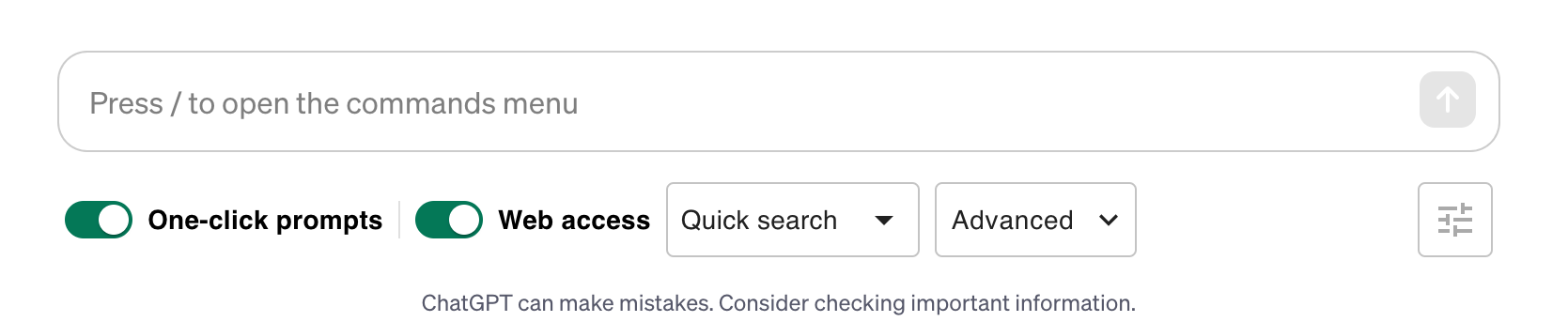
크롬에서 검색시에는 인터넷 검색을 통해 받은 내용을 활용하여 ChatGPT에게 질문 결과를 자동으로 확인 할 수 있습니다. 즉, 예전처럼 검색 결과로 나온 링크들을 일일히 찾아가서 내용을 보지 않아도, WebChatGPT를 사용하면 검색결과와 함께 요약된 주요 내용이 표시 됩니다. 그리고 ChatGPT를 사용할때는 질문 창에 질문은하면 자동으로 인터넷 검색 결과를 활용하여 답변을 생성해 줍니다. 그래서 LLM(Large Language Medel)이 가지는 훈련 데이터의 한계에서 벗어나서 최신 인터넷 정보를 활용하여 질문에 대답할 수 있습니다. WebCahtGPT 페이지에서 설명하는 주요 특징들은 아래와 같습니다. ---- 주요 특징들: 1️⃣ 웹 접근 - 검색어에 대한 웹 결과 얻기 - 완전한 통찰력을 위해 전체 검색 결과 페이지 스크랩 - 모든 URL에서 웹페이지 텍스트 추출 2️⃣ 원 클릭 프롬프트 - 원 클릭 ChatGPT 프롬프트 라이브러리 - 나만의 프롬프트 관리 3️⃣ AI로 검색 - 검색 결과 바로 옆에 AI 생성 응답 받기 - ChatGPT, Claude, Bard, Bing AI 제공 - 모든 인기 있는 검색 플랫폼과 호환
사용 방법 : 어떻게 설치하는가? 어떻게 사용하는가?
설치 방법은 간단합니다. 구글 크롬 앱 스토어에 가서 WebChatGPT를 검색하거나 그냥 구글 검색에서 WebChatGPT를 검색하여 나온 결과 중 설치 페이지의 링크를 클릭하시면 됩니다. 즉, 구글 크롬 브라우저에서 검색어 입력창에 "webchatgpt 인터넷 액세스가 가능한"을 입력하시고 제일 위에 나오는 링크를 클린하시면 됩니다.
그러면 WebChatGPT 앱 페이지로 이동하고 우측 상단에 있는 Chrome에 추가 버튼을 클릭하시면 자동으로 설치됩니다. 설치 후에 구글 검색창에서 검색하시면 결과가 보여질때 오른쪽에 WebChatGPT의 결과도 같이 보여 줍니다. 그리고 OpenAI의 ChatGPT 채팅을 이용할 때에도 아래와 같이 질문 입력창 위에 One-click prompts 와 Web access 버튼이 보입니다.
즉, 비트 들의 모임 중 하나만 1이고 나머지는 모두 0인 비트 들의 그룹을 원핫(One-hot)이라고 합니다.
그럼 인코딩(Encoding)이란 무엇일까요? 인코딩은 부호화라는 의미로 위키피디아에서는 아래와 같이 말하고 있습니다.
인코딩(encoding)은 컴퓨터를 이용해 영상 · 이미지 · 소리 데이터를 생성할 때 데이터의 양을 줄이기 위해 데이터를 코드화하고 압축하는 것이다.
쉽게 말하면 데이터를 압축/변형 하는 것은 인코딩, 이 압축/변형된 데이터를 원형으로 변환하는 것을 디코딩(Decoding)이라고 합니다.
그래서 원핫과 인코딩을 합친 One-hot Encoding(원핫 인코딩)이란
데이터를 One-hot 데이터 형태로 변형/압축하는 것
을 말합니다. 여기서 데이터는 이미지 데이터가 될 수도 있고 텍스트 데이터나 카테고리(범주형) 데이터가 될 수도 있습니다.
왜? 원핫 인코딩이 필요한가?
일반적인 인코딩은(부호화는) 정의에서 나온 것처럼 변형하거나 압축이 필요할 때 사용됩니다. 복잡하고 긴 이름이나 내용을 특정 규칙에 따라 변형 또는 매핑하여 축소할 때 효과적입니다. 파일 압축을 생각해보세요. 메일이나 메신저를 사용해서 용량이 큰 이미지나 동영상 파일을 전송할때 생각해보세요. 그냥 전송하는 것보다는 압축한 파일을 전송하는 것이 훨씬 빠르고 안정적입니다. 이처럼 원핫 인코딩의 경우에도 복잡한 데이터를 그대로 사용하지 않고 컴퓨터가 처리하기 쉽게 숫자로 변형해 주는 것입니다. 이렇게 함으로써 데이터를 처리하기 위해 필요한 메모리 양을 줄일 수 있고 처리를 빠르게 할 수 있습니다. 게다가 대부분의 통계나 머신러닝 모델들은 입력 데이터로 숫자값을 기본으로 합니다. 그래서 특히, 범주형 데이터를 원핫 인코딩해서 사용하는 경우가 많이 있습니다. 예를 들어서 주택 데이터 셋 중에서 주택 유형이라는 피처(데이터 항목)이 있고 이 항목의 실제 값들은 '아파트', ''연립주택', '다세대주택', '단독주택', '다중주택', '다가구주택', '기타' 로 구성되어있다고 하겠습니다. 이러한 값들을 그대로 모델의 입력값으로 사용할 수 없기 때문에 숫자로 바꾸어주는 것이 필요합니다. 그래서 이 법주형 데이터를 원핫 인코딩으로 변환할 경우, '아파트'는 '100000'으로 '연립주택'은 '010000'으로 변환되어 사용될 수 있습니다. 이렇게 원핫 인코딩된 값들은 분석 모델의 인풋 데이터로 사용할 수 있습니다.
어떻게 하나?
방법은 간단합니다. 범주형의 종류 개수(n) 크기의 벡터를 0으로 초기화하고, 특정 범주를 나타내기 위해 특정 위치의 값을 1로 설정하는 것 입니다. 위의 예에서도 잠깐 살펴본 주택 데이터 셋 예를 더 자세히 알아보겠습니다. 주택 유형이라는 범주형 데이터의 전체 범주 개수가 6개인 경우 벡터의 크기는 6이 됩니다. 이 벡터를 리스트로 표현하면 [0,0,0,0,0,0]이 됩니다. 크기가 6인 0벡터 이지요. 첫번째 범주인 '아파트'를 원핫 인코딩해보면 [1,0,0,0,0,0]로 나타 낼 수 있습니다. 첫번째 위치 값을 1로 설정하고 나머지는 모두 0인 원핫 벡터가 되었습니다. 다른 범주값까지 모두 원핫 인코딩 한 결과는 아래와 같습니다.
장점 및 단점
장점은 어떻게 인코딩/디코딩 되는지 쉽게 이해할 수 있다는 것 입니다. 구현도 쉽고 작은 데이터 셋에서 빠르게 동작한다는 장점이 있습니다.
단점은 범주가 추가되면 데이터의 크기가 바뀐다는 것입니다. 위에서 주택유형을 입력으로 쓰기 위해 6자리의 원핫 벡터로 인코딩해서 사용중이었는데 예를들어 전원주택 같은 새로운 주택유형이 하나 추가되면 7자리의 벡터로 바꾸어서 사용해야한 다는 것입니다. 이 말은 기존에 만들었던 모델이나 알고리즘에 변형이 필요하다는 의미 입니다. 매우 큰 변화이지요. 이처럼 향후의 확장성을 고려하여 더미 범주를 추가해서 인코딩하거나 해싱을 이용해서 인코딩 하기도 합니다. 이러한 문제를 OOD(Out Of Dictionary) 라고도 합니다. 예측이나 추론을 위해 원핫 인코딩을 실행했는데 모델이나 알고리즘을 개발할때에는 없던 새로운 범주가 입력되는 경우 인코딩 할 수 없어서 발생하는 에러를 말합니다.
정보저장을 위해 희소 벡터(Sparse Vector)를 사용하기 때문에 정보가 없는 공간에 대해서도 관리가 필요하게 되어서 메모리의 낭비가 발생한다는 것입니다. 위의 주택 유형 예에서 '아파트'를 '100000'으로 인코딩하면 첫번째 1만 값이 있고 나머지는 위치는 모두 정보가 없는 0이 차지하기 때문에 메모리 낭비가 발생하는 것입니다.
또 다른 단점은 범주형 데이터가 순서나 크기의 의미를 포함하고 있을 때 원핫 인코딩을 하게되면 이러한 정보들은 사용할 수 없게된다는 것입니다. 예를 들면 월요일, 화요일, 수요일, 목요일, 금요일, 토요일, 일요일을 원핫 인코딩하면 그저 0과 1일 집합으로 표현됩니다. 월요일은 [1,0,0,0,0,0,0], 토요일은 [0,0,0,0,0,1,0], 일요일은 [0,0,0,0,0,0,1] 이렇게 되겠지요. 이렇게 인코딩된 값들은 요일간에 순서나 크기를 표현하지 못합니다. 반면에 레이블 인코딩의 경우 일요일은 0, 월요일은 1, 화요일은 2, 수요일은 3, 목요일은 4, 금요일은 5, 토요일은 6으로 인코딩하면 요일간의 연계성 정보를 인코딩한 숫자에서도 찾을 수 있습니다. 즉, 수요일 3 다음에는 목요일 4라는 것을 알수 있지요. 이렇게 되면 5보다 큰 수가 의미를 갖을 수도 있습니다.
파이썬에서의 구현 방법
원핫 인코딩은 통계, 기계학습, 머신러닝, 딥러닝 등 쓰이는 범위가 넓습니다. 그래서 원핫 인코딩 기능은 여러 프레임웍과 페키지에서 제공하고 있습니다. 아래는 scikit-learn 패키지에서 구현한 예시 내용입니다.
# scikit-learn에서 필요한 모듈을 가져옵니다. from sklearn.preprocessing import OneHotEncoder
# 프로그램에서 사용할 인스턴스를 하나 만듭니다. one_hot_encoder = OneHotEncoder()
# 데이터 셋에서 범주형 데이터 항목의 값들을 인코더의 입력값 X로 설정 합니다. X = [['Apple'], ['Banana'], ['Cherry'], ['Date'], ['Egg'], ['Apple'], ['Cherry'], ['Cherry']] print('데이터 항목 X: ', X)
# 데이터 X를 이용해서 one hot encoding을 적용 실행 one_hot_encoder.fit(X)
# 인코딩된 카테고리들의 내용을 확인해 보는 명령어 categories = one_hot_encoder.categories_ print('범주 categories: ', categories)
# 특정 범주(여기서는 'Apple', X[0])에 해당하는 원핫 벡터를 찾아보는 명령어 one_hot_vector_for_alpha = one_hot_encoder.transform([X[0]]).toarray() print('Apple를 인코딩한 값(벡터): ', one_hot_vector_for_alpha)
# 특정 원핫 벡터(여기서는 'Apple'의 원핫 벡터 [[1. 0. 0. 0. 0.]])에 해당하는 범주 Category를 찾는 명령어 category_for_one_hot_vector = one_hot_encoder.inverse_transform(one_hot_vector_for_alpha) print('Apple 인코딩 벡터를 이용해서 찾은 범주 이름: ', category_for_one_hot_vector)
print('\n모든 범주와 원핫 인코딩을 출력 합니다.') for category in one_hot_encoder.categories_[0]: print(category,': \t', one_hot_encoder.transform([[category]]).toarray())
위의 내용을 실행하기 전에pip install sklearn명령을 통해 scikit-learn 패키지를 설치해 주어야 합니다. 아래는 패키지를 설치하고 위의 내용을 파일로 저장후 실행한 결과 입니다.
데이터 항목 X: [['Apple'], ['Banana'], ['Cherry'], ['Date'], ['Egg'], ['Apple'], ['Cherry'], ['Cherry']] 범주 categories: [array(['Apple', 'Banana', 'Cherry', 'Date', 'Egg'], dtype=object)] Apple를 인코딩한 값(벡터): [[1. 0. 0. 0. 0.]] Apple 인코딩 벡터를 이용해서 찾은 범주 이름: [['Apple']]
원핫 인코딩이 무엇인지에 대해서 알아보았고, 왜필요한지, 그리고 어떻게 구현할 수 있는지에 대해서 알아보았습니다. 이렇게 인코딩된 데이터를 이용하여 분석하거나 머신러닝 모델에서 입력 값으로 사용할 수 있습니다. 위에서 보신 것 처럼 Apple을 모델에서는 [[1. 0. 0. 0. 0.]]로 입력 받아 처리합니다. 결과 값을 분류하는 경우, 즉 과일 이름 중에 하나가 결과로 나와야하는 경우에는 역으로 [[1. 0. 0. 0. 0.]]로 나온 모델의 결과 값을 다시 'Apple' 로 바꾸어주는 것이 필요합니다. 이처럼 원핫 인코딩/디코딩은 범주형 데이터의 변환에 많이 쓰입니다.
Tokenization 은 텍스트를 토큰이라고 불리우는 작은 단위로 분리하는 것을 말합니다.
자연어처리 영역에서 토크나이제이션이란 위과 같이 정의할 수 있습니다. 여기에서 텍스트(text)는 문서나 문장 등을 말합니다. 즉, 인터넷 뉴스 기사, 블로그 글, 또는 이메일이나 간단한 채팅 내용 등도 모두 텍스트 데이터 입니다. 텍스트에서 데이터 분석이나 모델 개발 등 특정 목적을 위해 수집된 텍스트 데이터를 코퍼스(Corpus)라고말합니다. 말뭉치라고 하기도 합니다. 이러한 코퍼스를 데이터 전처리를 통해 Features를 만들게 됩니다. 그 첫 번째 작업이 말뭉치를 토큰이라고 불리우는 더 작은 단위로 나누는 토큰화입니다. 자연어 처리 과정중에서 토큰화의 위치를 설명하는 아래 그림에서 쉽게 이해하실 수 있으실 껍니다.
자연어 처리 과정 중 토큰화(Tokenization)의 위치
즉, 텍스트를 잘게 나누는 것을 토큰화라고 할 수 있습니다. 이렇게 잘게 나누는 방법은(토큰은) 보통 3가지가 있습니다. 단어, 서브단어, 문자 입니다. 문장도 가끔 포함됩니다. 코퍼스를 텍스트의 일부라고 했으니 일반적인 경우는 여러 문장이 들어있는 문단 또는 문서가 코퍼스 입니다. 그래서 문단이나 문서는 문장으로 나눌 수 있고, 문장은 다시 단어로 나눌 수 있고, 단어는 문자로 나눌 수 있습니다. 필요에 따라서 이렇게 세분화 하는 것이 토큰화(토크나이제이션, Tokenization)입니다. 토큰화는 데이터 전처리의 한 단계입니다. 토큰화, 정제, 정규화, 불용어 처리, 인코딩 등 여러 단계를 거쳐 실제 모델의 입력 데이터로 사용되는 피처(Features)가 만들어지게 됩니다.
왜 토큰화가 필요한가?
토큰화를 하는 이유는 자연어 처리에서 가장 일반적으로 전처리하는 방법중 하나이기 때문입니다. 가장 일반적인라는 말은 다시 말하면 많은 모델에서 이처럼 토큰화된 데이터를 필요로 한다는 의미 입니다. 실제로 자연어 처리 모델로 많이 사용되는 RNN, GRU, LSTM 등과 같은 신경망 모델들이 토큰화된 데이터를 이용해서 학습합니다.
또다른 이유는 바로 단어 사전을 만들기 위해서 입니다. 코퍼스에서 나오는 데이터를 중복없이 만들어서 모델에서 활용할 일이 많은데 이럴때 바로 토큰화라는 작업을 거쳐서 나온 토큰을 가지고 사전을 만듭니다. 예를 들어 단어로 토큰화를 한다면 단어수가 토큰 수가 되겠네요. 이렇게 만든 사전을 통해 기본적인 토큰의 출현 횟수 라든가, 또는 이런 횟수를 이용한 다양한 분석 방법을 이용할 수 있겠습니다. Word Count(BoW: Bag of Words), TF-IDF 등이 그 예가 되겠습니다.
어떤 토큰화를 해야할까요?
단어 토큰화(Word Tokenization)
가장 일반적인 토큰화 방법은 단어 토큰화 입니다. 특정 구분기호를 가지고 텍스트를 나누는 방법이지요. 영어의 경우 기본적으로는 공백을 구분자로 사용할 수 있습니다. 이러한 방법으로 토큰화하여 사용하는 모델중에 유명한 것이 Word2Vec 과 GloVe입니다. 한글의 경우 교착어라는 특징이 있어서 영어와 달리 구분자나 공백으로 단어 토큰화를 하면 성능이 좋지 않아서 잘 사용하지 않습니다. 한국어는 영어와 달리 조사가 큰 의미를 가지고 있습니다. 조사에 따라 문장내에서의 역할과 기능이 달라지기 때문에 매우 중요한 정보인데 (공백으로 나눈) 어절에서는 조사 정보를 정확히 사용하기 어렵습니다.
단어 토큰화에는 몇가지 안좋은 점이 있습니다. 먼저 OOV 문제가 있습니다. OOV란 Out Of Vocabulary의 약자 입니다. 즉, 입력된 데이터가 이미 만들어져 있던 단어사전에 없는 경우 입니다. 단어 사전은 (토큰의 리스트는) 코퍼스 데이터에서 만들어 지기 때문에 모든 단어를 가지고 있지 않습니다. 그래서 훈련때 없던 단어가 모델 예측 시 입력으로 들어올 수 있습니다. 입력을 받아서 해당 단어/토큰을 찾아서 처리해야하는데 없는거죠. 이 문제의 간단한 해결책은 UNK(Unknown Tocken)을 만드는 것입니다. 훈련 데이터에서 많이 출현하지 않는 단어/토큰을 UNK로 사전에 등록하는 것이지요. OOV문제는 해결할 수 있지만 모든 OOV단어가 같은 (UNK)가 의미하는 표현 값을 갖게 된다는 문제점이 있습니다. 즉, OOV 단어가 많으면 모델이 잘 동작하지 않을 수도 있겠네요. 또 다른 단어 토큰화의 문제는 단어 사전이 클 수 있다는 점 입니다. 사전에 포함된 단어가 많을 수록 사전에서 단어를 찾고 표현을 찾는데 시간이 많이 걸리게 됩니다. 모델의 응답시간에 문제가 생길 수 있다는 의미이고 필요한 경우 고용량의 메모리가 있는 서버 컴퓨팅 자원이 필요하다는 의미 입니다. 이러한 OOV 문제를 해결하는 방법중 하나가 문자 토큰화 입니다.
문자 토큰화(Character Tokenization)
문자 토큰화는 코퍼스를 문자로 분리하는 것입니다. 영어 같은 경우는 알파벳 26개 로 하나씩 분리하는 것이고, 한글의 경우 자음과 모음으로 분리하는 것입니다. 예를 들면 영어의 경우 'Tokenization' 을 T-o-k-e-n-i-z-a-t-i-o-n 으로 분리하는 것 입니다. 한글의 경우에는 "토큰화"를 ㅌ-ㅗ-ㅋ-ㅡ-ㄴ-ㅎ-ㅗ-ㅏ 로 분리하는 것 입니다. 이렇게 하면 단어 토큰화에서 있었던 OOV 문제가 해결됩니다. 모든 텍스트를 분리하면 결국 하나하나의 문자로 분리되기 때문에 모든 문자(영어 26개, 한글 자음/모음)를 사전에 등록해 놓으면 OOV 문제는 해결 됩니다. 그리고 메모리 문제도 해결됩니다. 왜냐하면, 영어 26개 알파벳이나 한글 자음/모음과 각가의 표현에 필요한 정보만 메모리에 저장하면 되기 때문에 메모리 문제도 없어집니다. 그런데 문자 토큰화에도 단점이 있으니, 바로 한 건의 입력 내용이 길어진다는 것입니다. 바로 위의 예에서도 볼 수 있듯이 "토큰화"를 ㅌ-ㅗ-ㅋ-ㅡ-ㄴ-ㅎ-ㅗ-ㅏ로 입력해야 합니다. 하나의 단어 인데도 이렇게 표현이 길지는데 문장이면 더 길어지겠지요. 이렇게 됨으로써 결국 단어와 단어 사이의 거리가 더 멀어지게 됩니다. RNN, LSTM 등 신경망 모델은 하나의 문장/텍스트에 해당하는 토큰 리스트를 순차적으로 입력 받습니다. 그런데 하나의 입력 길이가 길어지면 모델이 단어간의 관계를 학습하는 것을 어렵게 만듭니다. 이러한 문제점은 새로운 토큰화 방법이 필요함을 알 수 있습니다.
서브 단어 토큰화(Subword Tokenization)
서브 단어 토큰화는 문자 토큰화의 확장 버전 입니다. n개의 문자(n-gram characters)를 가지고 나누는 방법입니다. 서브 워드를 만드는 알고리즘 중에서 가장 유명한 것이 BPE(Byte Pair Encoding)입니다. 앞서 이야기한 단어 토큰화는 영어에는 잘 동작하는 편이지만 한국어에서는 잘 안된다고 말씀드렸는데요. 한국어는 형태소 분절 기반의 서브 단어 토큰화가 좋은 성능을 보여서 많이 사용됩니다. 문장을 형태소로 나누어서 각 형태소 별로 인코딩을 하는 방법입니다.
파이썬을 이용한 한글 토큰화
한글 텍스트 "나는 자연어처리와 파이썬을 정말 정말 좋아합니다." 라는 문장을 형태소 분석을 통해 토큰화를 해보겠습니다. 꼬꼬마 분석기를 이용했으며 코드와 설명은 아래와 같습니다.
# 필요한 페키지를 가져옵니다. from konlpy.tag import Kkma # 프로그램에서 사용하기 위한 인스턴스를 만듭니다. kkma = Kkma() # 텍스트 데이터를 설정 합니다. sentence = "나는 자연어처리와 파이썬을 정말 정말 좋아합니다." # 형태소분석 POS(Part Of Speech)를 실행합니다. results_of_pos = kkma.pos(sentence) # 결과를 출력해 봅니다. print(results_of_pos)
리스트 안에 튜플의 형태로 정리되어 결과가 나옵니다. 튜플의 첫번째 내용은 텍스트 내용이고 두번째 내용은 품사의 종류입니다. 예를 들면 ('나', 'NP')는 문장내 '나'를 분리해 냈으며 품사는 'NP' 대명사로 판단했습니다. 꼬꼬마 형태소 분석기에 대한 품사 태그표는 여기를 참고해 주세요.
요약
이번에는 먼저 토큰화의 정의를 살펴보았습니다. 토큰화란 텍스트/코퍼스를 작은 단위의 토큰으로 나누는 방법이라고 정의 했습니다. 토큰화 방법에는 단어, 문자, 서브단어가 있고 각각의 장점/단점을 알아보았습니다. 마지막으로는 파이썬 언어를 이용하여 한글을 토큰화하는 사례를 살펴보았습니다. 토큰화를 거처 생성된 토큰 들은 정재, 정규화, 불용어 처리, 인코딩 등의 피처 엔지니어링(Feature Engineering) 단계를 거쳐서 모델의 인풋으로 사용될 피처(Features)로 만들어 집니다. 이러한 단계를 거쳐서 워드 클라우드, 자동 번역, 질의 응답(QnA) 등 다양한 자연어 처리 모델과 어플리케이션을 만들 수 있습니다.
TF-IDF 는 BoW(Bag of Words)와 마찬가지로 텍스트 데이터를 (컴퓨터에서 사용하기 위해) 표현하는 방법중 한가지 방법 입니다. 정보 검색과 텍스트 마이닝에 많이 쓰입니다. 특히, 이 방법은 단어의 출현 빈도를 가지고 단어의 중요도를 표현하는 방법입니다. 그래서 해당 문서에서의 단어 출현 횟수와 다른 전체 문서에서의 출현 횟수를 고려해서 중요도를 계산합니다. 해당 문서에서의 단어 출현 횟수는 많으면 많을 수록 단어의 중요도가 더 높아지고(Term Frequency), 다른 전체 문서에서의 출현 횟수가 많아지면 많아 질수록(다른 문서에서도 많이 쓰이면 쓰일 수록) 중요도가 떨어지게하는(Inverse Document Frequency) 숫자를 만드는 방법 입니다. 예를 들어 보겠습니다. '노란 사자 왕' 이란 검색어와 가장 적절한 문서를 찾으려면 어떻게 해야할 까요? 가장 간단한 방법은 각 단어가 포함되어 있는 문서를 찾는 것일 것입니다. 그런데 이런 문서가 10,000개 있다면 어떻게 해야 할까요? 네, 여러번 '노란', '사자', '왕' 이란 단어가 들어가 있으면 더 적절한 문서라고 할 수 있을 것 같습니다. 그런데 이렇게 해서 다시 필터링해보니 100건이 나왔다고 합시다. 여러번 나왔으니 더 적절한 문서라고 할 수 있지만 문서의 길이를 고려하지 못해서 전체 문서에서의 단어 중요도가 반영되지 못했습니다. 1페이지 문서에서 10번 나온 것과 100페이지 문서에서 10번 나왔다면 1페이지에서 10번 나온 문서가 더 밀접한 관계가 있다고 말할 수 있습니다. 그래서 문서의 길이를 고려한 출현 횟수를 산정하는 방법이 바로 Term Frequency 입니다. 그래서 간단한 공식으로는 단어 출현횟수/ 문서내 전체 단어수가 되겠습니다. 그럼 두번째 전체 문서에서의 출현 횟수 왜 필요할까요? 문서중에는 의미가 없는 단어들도 매우 많습니다. 행태소 분석시 나오는 '는', '를', 'ㅂ니다' 같은 요소들은 의미는 없지만 일반적으로 매우 많이 출현하는 단어에 해당합니다. 이러한 단어들에게는 매우 작은 값으로 계산되는 것이 필요하겠습니다. 그러면 이런 숫자는 어떻게 계산할까요? 위에서 설명한 것처럼 모든 문서에서 나타나면 안 중요한 단어이고 해당문서에서만 나타나면 중요한 단어인 것이지요. 이렇게 만들려면 전체 문서수와 해당 단어가 나타난 문서수의 비율로 계산할 수 있겠습니다. 전체 문서수 / 해당 단어 출현 문서수 이렇게 계산하면 되겠군요. 100 개 문서중에 1번 나타난 단어(100/1=100)와 100개 문서중에 10번 나타난 단어(100/10=10)는 중요도가 달라집니다. 그런데 이렇게 하면 전체 문서와 단어 출현 문서수가 클 경우 중요도 차이가 너무 크게 됩니다. 그래서 여기에 log 를 적용하여 숫자를 작게 만듭니다. log(100) = 2, log(10) = 1. 아까는 차이가 9였는데 이제는 1이 되었네요. 그래서 간단한 공식으로는 log(전체 문서수/해당 단어 출현 문서수)가 됩니다. 이것이 Inverse Document Frequency입니다. 그런데 다른 자료들을 보면 계산하는 방법이 이렇게 간단하지 않고 복잡하고, 방법도 여러가지가 있는 걸까요? 그 이유는 좀더 정확한 계산을 위해서 단순한 출현 횟수를 그대로 사용하지 않고 변환을 하기 때문에 그렇습니다. 위에서 log를 적용한 것처럼 말이죠. 중요한 것은 기본을 이해하는 것 입니다. 기본을 이해해야 변형을 이해하기 쉽습니다. 기본은 위에서 말씀 드린 것 처럼 어렵지 않습니다.
큰 숫자에 대응하기 위해 log를 사용하고 분모/분자가 0이 되면 안되므로 문서가 없을 때를 대비해서 분모/분자에 1을 더해줍니다. 그래서, TF-IDF의 공식은 아래와 같습니다.
해당 단어의 TF-IDF = Term Frequency X Inverse Document Frequency 해당 단어의 TF-IDF = TF(t,d) X IDF(t, D) 해당 단어의 TF(t,d) = log (f(t,d) + 1) 해당 단어의 IDF(t, D) = log (D / ( {d in D : t in d} ) + 1) ) t: 해당 단어 d: 해당 문서 D: 전체 문서 개수
2. TF-IDF 계산 해보기
위에서 말씀드린 공식을 이용해서 실제 TF-IDF 값을 계산해 보겠습니다.
Data
아래와 같은 데이터를 가정하겠습니다.
총 문서 데이터 개수, D = 10
각 문서 별 내용
d1 = “Iloveapple"
d2 = “Ilovepeach”
d3 = “Ilovelion"
d4 = “Youlovelemon”
d5 = “Youlovehorse"
d6 = “Youlovelion”
d7 = “Welovetiger"
d8 = “We hateapple”
d9 = “We hatebanana"
d10 = “They hatepeach”
d1의 tf-idf 구하기
문서 d1에 대하여 TF-IDF를 구합니다. ln은 자연로그 입니다.
t = “I” d1 = “I love apple" tf(t,d) = tf(“I”,d1) = ln (1 + 1) = 0.6931 (count 로 할때, 문서 d에서 t가 발견되는 건수) idf(t, D) = log (D / {d in D : t in d} ) = ln(10 / (3 + 1)). = ln(2.5) = 0.9162 10개 문서중 3개 문서에서 I 가 발견됨 “I” tfidf = tf(“I”,d1) * idf(“I", 10) = ln(2) * ln(2.5) = 0.6931 * 0.9162 = 0.6350 ("I"의 TF-IDF입니다.)
t = “love” d1 = “I love apple" tf(t,d) = tf(“love”,d1) = ln (1 + 1) = 0.6931 (count 로 할때, 문서 d에서 t가 발견되는 건수) idf(t, D) = log (D / {d in D : t in d} ) = ln(10 / (7 + 1) ) = ln(1.25) = 0.22314 10개 문서중 7개 문서에서 love 가 발견됨니다. “love” tfidf = tf(“love”,d1) * idf(“love", 10). = ln(2) * ln(1.25) = 0.6931 * 0.22314 = 0.15466 (love라는 단어가 많은(7개) 문서에서 나타나기 때문에 tfidf 값이 비교적 작습니다. 단어가 주는 차별성/특성이 작다고 할 수 있습니다.)
t = “apple” d1 = “I love apple" tf(t,d) = tf(“apple”,d1) = ln (1 + 1) = 0.6931 (count 로 할때, 문서 d에서 t가 발견되는 건수) idf(t, D) = log (D / {d in D : t in d} ) = ln(10 / (2 + 1) ) = ln(3.3333) = 1.2039 10개 문서중 2개 문서에서 apple 가 발견됩니다. “apple” tfidf = tf(“apple”,d1) * idf(“apple", 10). = ln(2) * ln(2.4285) = 0.6931 * 1.2039 = 0.8344 (apple라는 단어가 적은(2개) 문서에서 나타나기 때문에 tfidf 값이 비교적 큽니다. )
t = “peach” d2 = “I love peach” tf(t,d) = tf(“peach”,d1) = ln (1 + 1) = 0.6931 (count 로 할때, 문서 d에서 t가 발견되는 건수) idf(t, D) = log (D / {d in D : t in d} ) = ln(10 / (2 + 1) ) = ln(3.3333) = 1.2039 10개 문서중 2개 문서에서 peach 가 발견됩니다. “peach” tfidf = tf * idf = 0.6931 * 1.2039 = 0.8344
d2 = “I love peach” = [0.6350, 0.15466, 0.8344]
d10의 tf-idf 구하기
t = “They” d10 = “They hate peach” tf(t,d) = tf(“They”,d10) = ln (1 + 1) = 0.6931 (count 로 할때, 문서 d에서 t가 발견되는 건수) idf(t, D) = log (D / {d in D : t in d} ) = ln(10 / (1 + 1)). = ln(5) = 1.6094 10개 문서중 1개 문서에서 They 가 발견됨 “They” tfidf = tf(“They”,d10) * idf(“They", 10) = ln(2) * ln(2.5) = 0.6931 * 1.6094 = 1.1154 (They라는 단어가 하나의 문서에서 나타나기 때문에 tfidf 값이 매우 큽니다. )
t = “hate” d10 = “They hate peach” tf(t,d) = tf(“hate”,d1) = ln (1 + 1) = 0.6931 (count 로 할때, 문서 d에서 t가 발견되는 건수) idf(t, D) = log (D / {d in D : t in d} ) = ln(10 / (3 + 1) ) = ln(2.5) = 0.9162 10개 문서중 3개 문서에서 hate 가 발견됨 “hate” tfidf = tf(“hate”,d1) * idf(“hate", 10). = ln(2) * ln(1.25) = 0.6931 * 0.9162 = 0.6350 (hate라는 단어가 적은 문서(3)에서 나타나기 때문에 tfidf 값이 비교적 큽니다. )
t = “peach” d10 = “They hate peach” tf(t,d) = tf(“peach”,d1) = ln (1 + 1) = 0.6931 (count 로 할때, 문서 d에서 t가 발견되는 건수) idf(t, D) = log (D / {d in D : t in d} ) = ln(10 / (2 + 1) ) = ln(3.3333) = 1.2039 10개 문서중 2개 문서에서 peach 가 발견됩니다 “peach” tfidf = tf(“peach”,d1) * idf(“peach", 10). = ln(2) * ln(2.4285) = 0.6931 * 1.2039 = 0.8344 (peach라는 단어가 적은(2개) 문서에서 나타나기 때문에 tfidf 값이 비교적 큽니다. )
d10 = “They hate peach” = [1.1154, 0.7614, 0.8344]
해석: 3개의 문서중에는 d2과 d10이 가장 유사하고, d1과 d10은 완전히 다른 문서이다.
상기와 같이 문서간의 유사도 계산 뿐만아니라 키워드(검색어)를 가지고 유사도를 계산하면 유사한 문서를 가져오는 정보 검색에 사용할 수 있습니다.
3. TF-IDF의 장점 및 단점
1. 위 예시에 행렬 테이블에서도 보이는 바와 같이 0이 많이 들어있는 행렬 테이블이 만들어져서 문서의 길이가 길고 중복된 단어가 적을 수록 더 비효율 적입니다. sparce matrix (many number of 0 value)
2. 간단하게 단어의 개수로 표현되어 구현이 쉽지만 단어 위치의 의미를 파악하지는 못합니다. 문서 d1에 있는 i 와 문서 d10에 있는 hate 가 다른 단어 임에도 불구하고 같은 값 0.6350을 갖습니다. simple count of words, not present meaning of position(‘i' in d1 and ‘hate' in d10 have same value, 0.6350)
3. TF-IDF 메트릭스(행렬)에 없는 새로운 단어가 들어오면 계산할 수 없습니다. cold start, new words come, need new matrix(‘happy’?...) 이러한 부작용을 줄이기 위해 BoW(Bag of Words)에서와 마찬 가지로 더미 워드나, hashing 기법 등을 이용할 수 있습니다.
이렇게 정보검색과 텍스트 마이닝에 많이 쓰이는 단어의 중요도 표현 방법중 하나인 TF-IDF에 대해서 알아보고 실제로 계산을 해보았으며, 장점과 단점에 대해서도 이야기해 보았습니다.