(좋은 모델을 싸게 만들 수 있었던 이유는) 엔지니어링을 통해 저사양의 서버를 효과적으로 사용해서 (엔지니어링 기법 등 별도 포스팅)
(저사양의 서버를 효과적으로 사용할 수 있었던 이유는) 좋은 엔지니어들이 있어서
영향도 분석
현상
NVIDIA 주가 폭락
2025년 1월 27일 월요일 하루만에 NVIDIA의 주가가 약 17%가까이 급락했습니다. 거의 6000억 달러의 시장가격이 사라졌다고 합니다.
1월 27일 NVIDIA 주가 16.97% 급락
엔비디아 주가의 차트(1월 27일 급락)
나스닥 지수 폭락
뿐만아니라 특기 기술 주식들이 상장되어있는 나스닥도 급락했습니다.
원인분석
1. DeepSeek App Download 1위
위에서 처럼 왜 이렇게 급락한 것 일까요? 여러가지가 있겠지만 그 주요 이유는 미국 App Store 에서 무료 App중에서 다운로드 1등을 찍은 앱이 DeepSeek라는 앱이었기 때문입니다. DeepSeek라는 앱은 ChatGPT 앱 또는 Perplexity 앱과 같은 AI Assistant App입니다.
DeepSeek라는 회사나 이름은 잘 모르겠지만 다운로드 1등한 것이 뭐가 큰 문제여서 엔비디아 주가가 폭락한 걸까요?
2. (DeepSeek App이 1위 한 이유는) 좋은 서비스를 무료로 제공해서
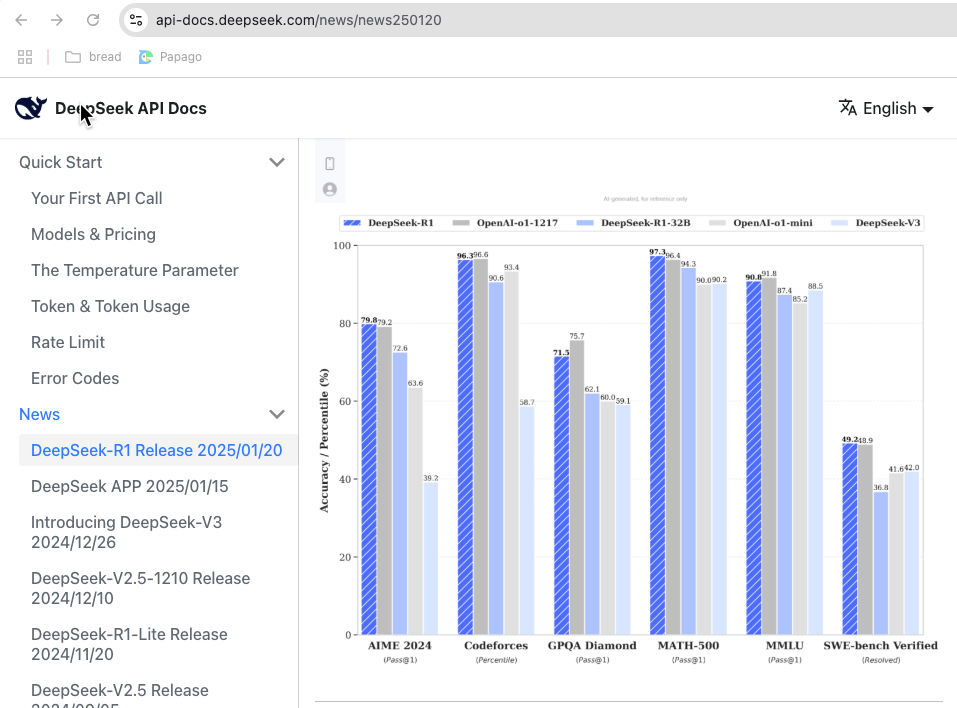
먼저 왜 DeepSeek가 미국 앱스토어에서 다운로드 1등을 했는가를 알아볼 필요가 있습니다. DeepSeek가 성능좋은 서비스를 무료로 제공했기 때문에 많은 앱 다운로드가 있었고 그래서 다운로드 1등을 했습니다. DeepSeek 앱은 DeepSeek-V3를 기본으로 하는데 이 모델의 성능이 아래와 같이 다른 모델과 비교해서 동등하거나 보다 우수한 부분도 있거든요.
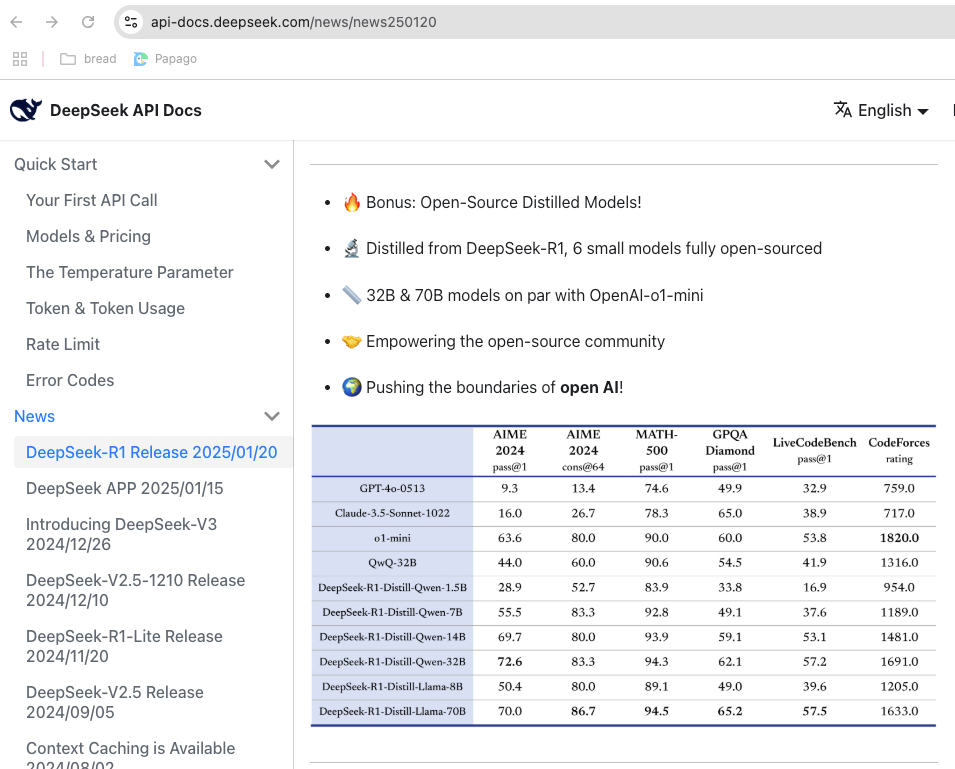
특히 놀라운 점은 1월 20일에 발표한 DeepSeek-R1의 경우 수학문제풀이와 코딩 밴치마크 테스트에서 OpenAI를 능가하는 성능을 보인 것 입니다.
MATH-300(수학)과 SWE-bench(코딩)에서 우수합니다.
특히 수학(MATH-500)에서 OpenAI의 o1-mini보다 좋은 점수를 보입니다.
이처럼 좋은 모델을 (ChatGPT 에서는 별도 비용을 지불해야하지만) DeepSeek 앱에서는 무료로 사용할 수 있기 때문에 DeepSeek App이 미국 App Store에서 다운로드 1위를 할 수 있었습니다.
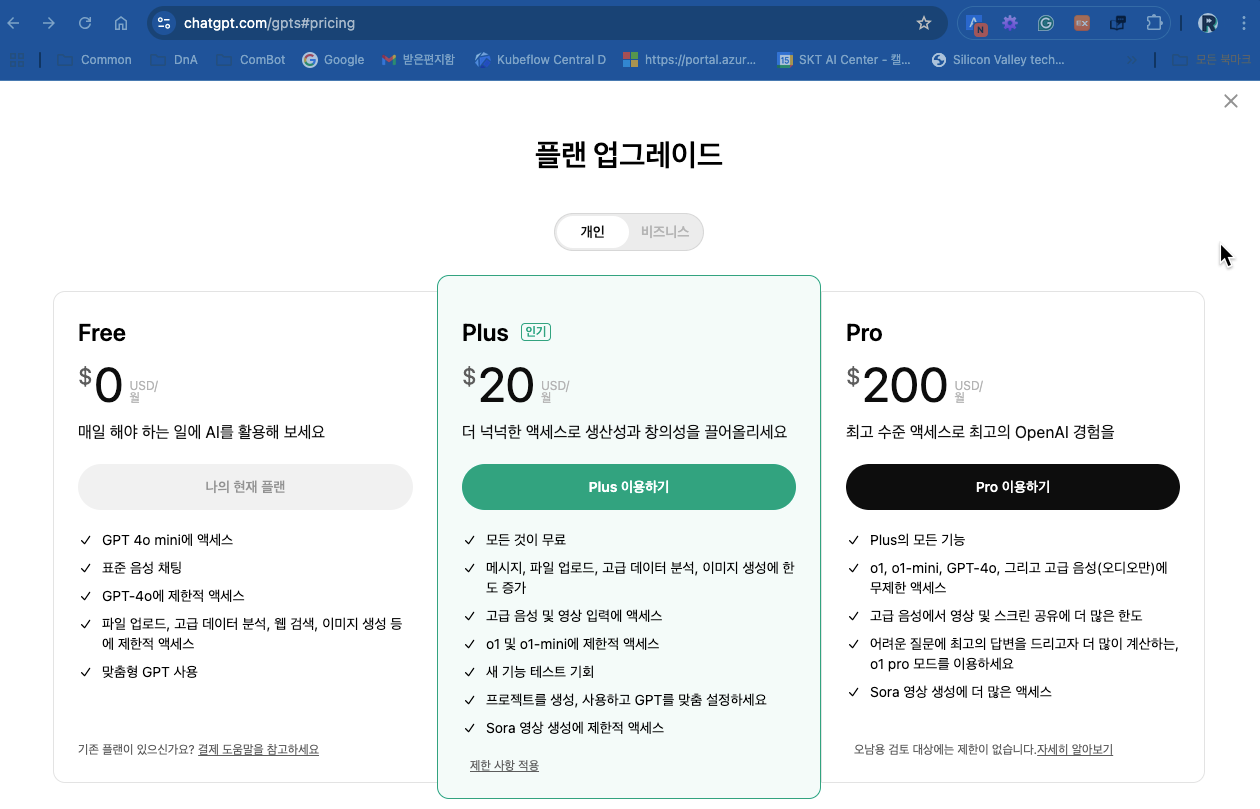
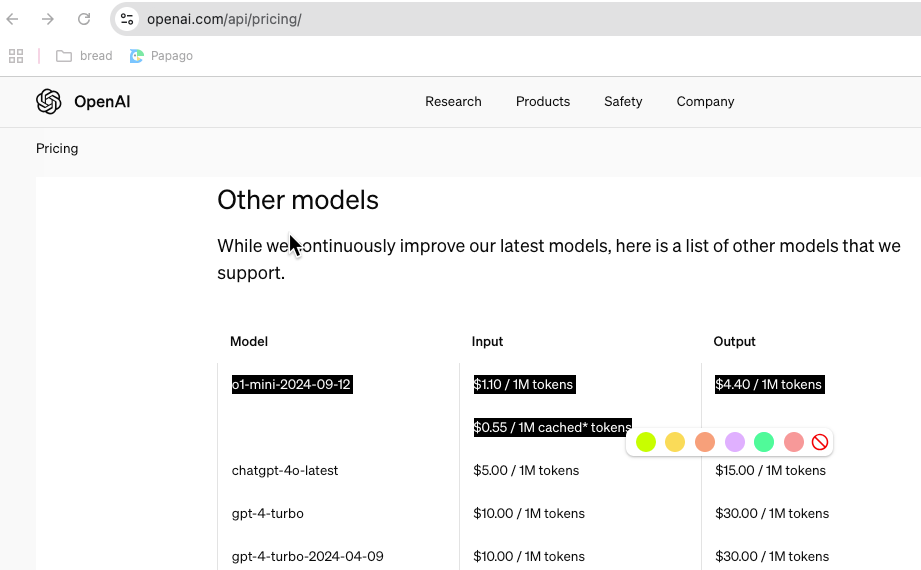
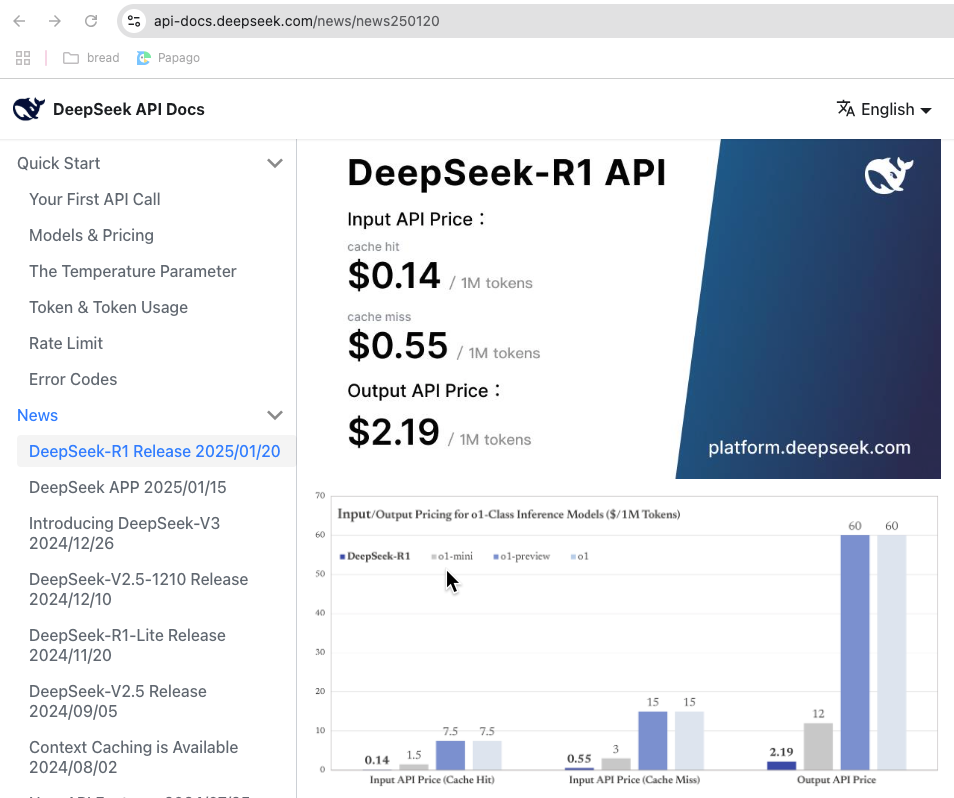
조금 다른 이야기이지만 API 비용도 저렴합니다. DeepSeek는 훈련도 싸게하고 추론(서비스)도 저렴하게 할 수 있기 때문에 서비스도 무료나 저렴하게 제공합니다. 예를들어 OpenAI ChatGPT에서는 유료 가입회원에게만 제공하는 o1 모델과 유사한 성능의 서비스를 무료로 제공하고 있습니다.
OpenAI는 o1모델이용을 위해 Plus 요금제 가입이 필요
OpenAI에서 제공하는o1-mini 모델의 API 비용
DeepSeek-R1 모델의 API비용 및 OpenAI o1-mini와 비교
3. (좋은 서비스를 무료로 제공할 수 있었던 이유는) 좋은 모델을 싸게 만들어서
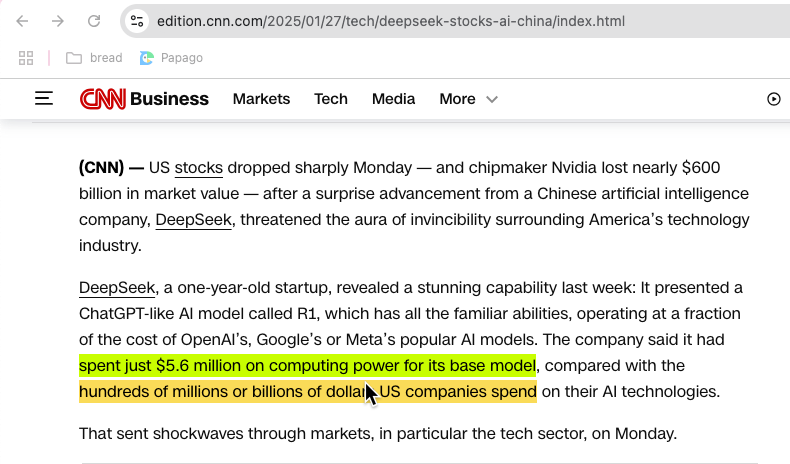
DeepSeek는 OpenAI의 Chat-GPT나 Meta의 Llama의 성능을 낼 수 있는 또 다른 모델(DeepSeek-R1)을 매우 적은 비용으로 만들었습니다. 무려 10분의 1 도 안되는 비용으로 말이지요. DeepSeek에서는 5.6M 달러가 들었다고 발표했는데 다른 회사에서는 수억 달러 또는 수십억 달러 정도 들었다고 했거든요.
4. (좋은 모델을 싸게 만들 수 있었던 이유는) 엔지니어링을 통해 저사양의 서버를 효과적으로 사용해서
이렇게 저비용으로 모델을 만들고 서비스할 수 있었던 이유에는 (데이터, 환경, 인프라, 리소스 등) 여려가지가 있겠지만 저는 한마디로 말하면
DeepSeek가 엔지니어링을 잘했다
라고 말할 수 있겠습니다. 모델을 개발하고 서비스할 때 하드웨어를 효율적으로 운영할 수 있도록 여러 테크닉을 적용해서 개발했기 때문입니다. DeepSeep에서 발표한 모델은 많은 제약과 한계를 극복하기 위해 다양한 아이디어의 기술을 적용했습니다. 어떻게 엔지니어링을 했는지는 별도 포스팅 엔지니어링을 잘해서 비용 효율적인 모델과 서비스를 만들었습니다. 이처럼 좋은 모델을 만든 것도 대단한데 더욱 놀라운 것은 이러한 모델을 NVIDIA H800이라는 서버를 이용해서 만들었다는 것 입니다. DeepSeek는
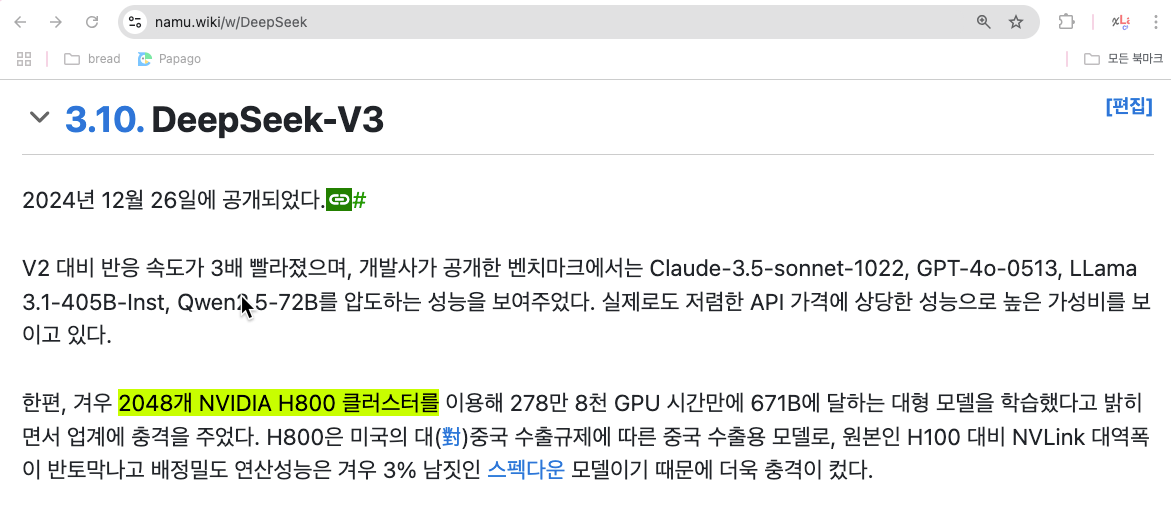
NVIDIA H800서버 2048대를 클러스터로 만들어서 훈련
했습니다. 그 이유는 미국의 규제로 인하여 중국에 납품하는 NVIDIA 서버는 제한되어있기 때문입니다. 그래서 더 좋은 서버를 사용할 수 없었습니다. H800서버는 H100서버의 다운 스펙서버입니다. 그럼에도 불구하고 더 짧은 시간의 훈련시간과 좋은 성능을 달성했으니 놀라지 않을 수 없습니다.
나무위키 설명 내용중 일부
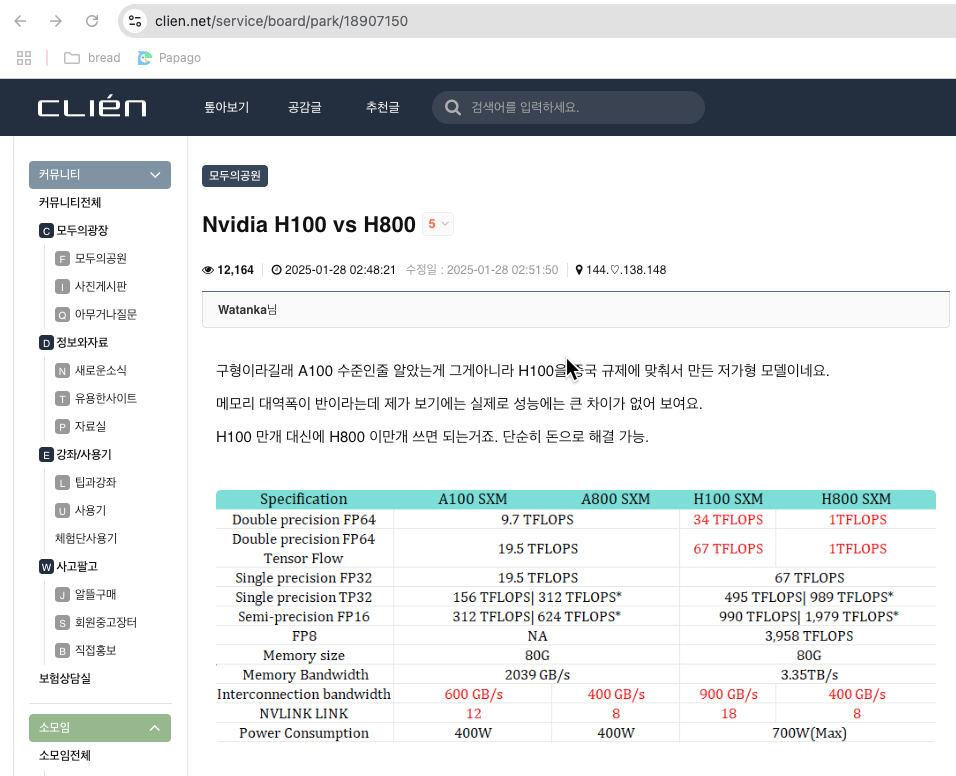
클리앙 글
위 클리앙의 내용을 보니 구체적으로, FP64일때의 성능과 NVLink, Interconnection bandwidth에서 차이가 나네요.
5. (저사양의 서버를 효과적으로 사용할 수 있었던 이유는) 좋은 엔지니어들이 있어서
그럴 수 있었던 것은 DeepSeek회사 직원들의 배경이 주식자동거래 프로그램을 만드는 퀀트들이었다고 하네요. 그래서 최적화를 위한 다양한 레벨의 인지니어링이 가능했다고 생각합니다.
영향도 분석(별도 포스팅)
미국 정부 먼저 이번 DeepSeek 이슈로 인하여 AI에 대해서 미국 리더십을 확실하게 가져 가려고 했던 트럼프 정부를 긴장시킨 것은 맞는 것 같습니다. 트럼프가 미국 기업에게 알람이 되어야 한다고 이야기 했으니까요. 기존에는 AI 개발을 위해서 인프라가 중요하고, 인프라에서 우위를 점하고 있는 미국이 당연히 계속해서 앞서 나갈 것으로 생각했는데, 그리고 그래서 더욱 앞서 나가기 위해서 향후 투자 계획도 발표했는데 안좋은 인프라에서도 AI개발이 가능하다고하는 사례가 나왔기 때문이지요. 그렇기 때문에 중국에 대한 견제는 더욱 심해질 것으로 예상됩니다. 새로운 규제가 더 나올 수도 있겠지요. 그리고 AI 경쟁에서의 스푸트니크 쇼크를(소련이 먼저 인공위성을 쏘아올려서 미국을 깜짝 놀라게 만들었던 사건을) 방지하기위해 AI 관련 투자에 더욱 노력할 수 있습니다. AI 관련 미국 기업 위에서 말한 것처럼 저사양의 서버로도 훈련하고 서비스할 수 있다면 굳이 비싼 서버를 사용할 필요가 없지요. 고사양의 비싼 서버를 구매할 필요가 당분간은 줄어들 것으로 예상됩니다. 그래서 엔비디아 같은 기업의 경우 매출 감소가 예상이되니 주가가 하락한 것이죠. 그러나 반대로 적은 비용으로도 AI 모델 개발이 가능해지니 더 많은 기업들이 뛰어들어서 전체적인 서버 수요는 늘어날 것이라는 예상도 있습니다. Software 중심의 Big Tech기업의 경우 당연히 엔지니어링에 더욱 집중 할 것으로 예상됩니다. 좋은 사례를 보았으니 유사하거나 더 좋은 방법을 찾고자 노력할 것으로 예상됩니다. AI 관련 한국 기업 같은 맥락에서 한국의 Software 기업에게도 기회가 생겼다고 할수 있습니다. 적은 비용으로 고성능의 품질 좋은 AI서비스를 만들 수 있게되었으니 SK하이닉스나 삼정전자 같은 Hardware 기업은 단기적으로 엔비디아와 같이 실적이 줄어들 수 있을 것 같습니다. 서버 수요가 늘어난다고 해도 저사양, 낮은 단가의 서버이기 때문에 높은 부가가치를 바라기는 어렵게 되는 거죠.
지난 주 AWS Partner Tech Grue Community Meet-up 에 다녀 왔습니다.
TGC는 AWS 에서 Partner Engineer를 대상으로 기술 관련 공유 토의하는 모임 입니다. 올해 그 첫번째 모임으로 지난주 강남 센터필드에서 열렸어요. 오신 분들 모두 파트너사의 기술 관련 업무를 (한가닥?) 하시는 분들이었어요. 조건이 파트너사의 직원이고 AWS 자격증 요건 또는 AWS Ambassador 등 여러가지가 있었습니다. 어려울 것 같았는데 저도 운 좋게 참여하게 되었습니다.
이번은 올해 첫 모임으로 전반적인 계획을 공유하는 시간이었고요, 기술 모임인 만큼 Ambassador 분들의 발표도 있었습니다.
저녁 퇴근후에 모임이다보니 출출함을 달래줄 피자와 치킨, 맥주와 음료 등도 제공해 주셨습니다.
새로운 기술과 트랜드 그리고 이에 대한 AWS의 새로운 기능 들을 먼저 만나볼 수있을 것 같아서 기분이 설래입니다. 앞으로 따끈따끈한 소식 전하겠습니다. 감사합니당~~~
지난 시간에는 LCEL Get-started를 통해서 LCEL의 간단하면서 다양한 예시를 알아보았습니다.
이번 시간에는 LCEL을 사용하는 이유에 대해서 알아보도록 하겠습니다. 즉, 사용하면 무엇이 좋은지 어떤 가치가 있는지 알아보겠습니다. 참고로 LCEL Get-started를 먼저 보고 오시면 이해에 도움이 됩니다. 혹시 안보셨다면 먼저 읽어보시기를 추천 드립니다.
LCEL은 간단한 콤포넌트 부터 복잡한 체인을 쉽게 만들 수 있게 합니다. 바로 다음과 같은 것들을 이용해서 만듭니다.
1. 통일된 인터페이스:
모든 LCEL 객체는 Runnable 인터페이스를 구현합니다.Runnable은 호출하는 메소드들의 공통 집합을 정의합니다.(invoke, batch, stream, ainvoke,...등과 같은...)이것은LCEL객체가 자동적으로 이러한 호출들을 지원할 수 있게 만듭니다. 즉, LCEL 객체로 만든 모든 체인은 하나의 LCEL객체라는 것을 말합니다.
2. 원시도구들의 구성:
LCEL의 가치를 이해하기 위해서, LCEL 없이 비슷한 기능을 어떻게 개발하는 지 생각해보고 동작하는 지를 살펴보는 것은 도움이 됩니다. LCEL은 콤포넌트들을 병렬화하고, fallbacks을 추가하고, 체인 내부의 구성을 동적으로 바꾸는 등을 통해서체인을 쉽게 구성하게 해줍니다. 이번 포스팅에서는 지난 번 LCEL Get-started의 내용에 있던 기본 예시를 다루어 보겠습니다. 간단한 프롬프트와 모델이 결합된 체인을 다루어 볼껀데요, 이것은 이미 많은 기능들이 정의되어 있습니다. 이것을 재생성하는 데 필요한 것이 무엇인지 살펴보겠습니다.
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
prompt = ChatPromptTemplate.from_template("Tell me a short joke about {topic}")
model = ChatOpenAI(model="gpt-3.5-turbo")
output_parser = StrOutputParser()
chain = prompt | model | output_parser
프롬프트, 모델, 아웃풋 파서를 연결한 체인을 만듭니다.
이제부터 다음 내용을 구현할 때 두가지 경우의 코드를 비교하겠습니다. 즉, LCEL 없이 구현할 때와 LCEL로 구현할 때의 코드를 보겠습니다.
제일 간단한 사용예를 보면, 토픽(주제) 문자열을 전달해 주 농담 문자열을 받는 것 입니다. 아래는 이러한 내용을 LCEL 없이 개발했을 때와 LCEL로 개발했을 때의 차이를 보여 줍니다.
LCEL 없이 만드는 경우
from typing import List
import openai
prompt_template = "Tell me a short joke about {topic}"
client = openai.OpenAI()
def call_chat_model(messages: List[dict]) -> str:
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages,
)
return response.choices[0].message.content
def invoke_chain(topic: str) -> str:
prompt_value = prompt_template.format(topic=topic)
messages = [{"role": "user", "content": prompt_value}]
return call_chat_model(messages)
invoke_chain("ice cream")
LCEL로 만드는 경우
from langchain_core.runnables import RunnablePassthrough
prompt = ChatPromptTemplate.from_template(
"Tell me a short joke about {topic}"
)
output_parser = StrOutputParser()
model = ChatOpenAI(model="gpt-3.5-turbo")
chain = (
{"topic": RunnablePassthrough()}
| prompt
| model
| output_parser
)
chain.invoke("ice cream")
비교 이미지
Stream
만약에 결과로 스트림을 원한다면 위에서 LCEL 없이 만든 함수의 내용을 수정해야 합니다.
LCEL 없이 만드는 경우
from typing import Iterator
def stream_chat_model(messages: List[dict]) -> Iterator[str]:
stream = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages,
stream=True,
)
for response in stream:
content = response.choices[0].delta.content
if content is not None:
yield content
def stream_chain(topic: str) -> Iterator[str]:
prompt_value = prompt.format(topic=topic)
return stream_chat_model([{"role": "user", "content": prompt_value}])
for chunk in stream_chain("ice cream"):
print(chunk, end="", flush=True)
LCEL로 만드는 경우
for chunk in chain.stream("ice cream"):
print(chunk, end="", flush=True)
LCEL로 만드는 경우는 그저 두 줄의 코드면 충분합니다.
Batch
병렬적으로 여러 입력을 배치로 실행하기 원한다면 또 다시 새로운 함수가 필요합니다.
LCEL 없이 만드는 경우
from concurrent.futures import ThreadPoolExecutor
def batch_chain(topics: list) -> list:
with ThreadPoolExecutor(max_workers=5) as executor:
return list(executor.map(invoke_chain, topics))
batch_chain(["ice cream", "spaghetti", "dumplings"])
import os
from langchain_community.chat_models import ChatAnthropic
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough, ConfigurableField
os.environ["LANGCHAIN_API_KEY"] = "..."
os.environ["LANGCHAIN_TRACING_V2"] = "true"
prompt = ChatPromptTemplate.from_template(
"Tell me a short joke about {topic}"
)
chat_openai = ChatOpenAI(model="gpt-3.5-turbo")
openai = OpenAI(model="gpt-3.5-turbo-instruct")
anthropic = ChatAnthropic(model="claude-2")
model = (
chat_openai
.with_fallbacks([anthropic])
.configurable_alternatives(
ConfigurableField(id="model"),
default_key="chat_openai",
openai=openai,
anthropic=anthropic,
)
)
chain = (
{"topic": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
요약
이번 시간에는 LCEL을 실제로 사용할 때와 안했을 때의 차이 비교를 통해서 LCEL이 제공하는 가치에 대해서 알아보았습니다. LCEL이 통일된 인터페이스를 제공하고 많은 원시 구성 요소들을 제공하기 때문에 간단한 메소드 호출 만으로 많은 기능을 대신할 수 있음을 사례로 살표 보았습니다. 이러한 사례를 통해서 단순하고 간결한 코드 작성으로 구현이 가능함을 확인 하였습니다.
Next Steps
LCEL에 대한 학습을 계속하려면 다음을 권장합니다:
여기서 부분적으로 다룬 LCEL 인터페이스에 대해 전체 내용을 자세히 읽어보세요.
LCEL이 제공하는 추가적인 구성 기본 요소에 대해 학습하기 위해서 How-to 섹션을 탐험하세요.
공통 사용 사례에 대한 LCEL 동작을 보려면 Cookbook 섹션을 확인하세요. 그 다음에 살펴볼 좋은 사용 사례는 검색 증강 생성입니다.