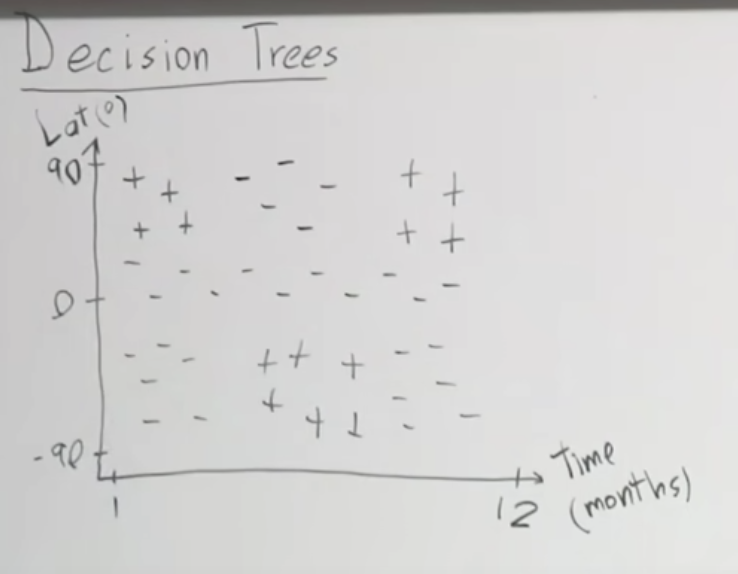
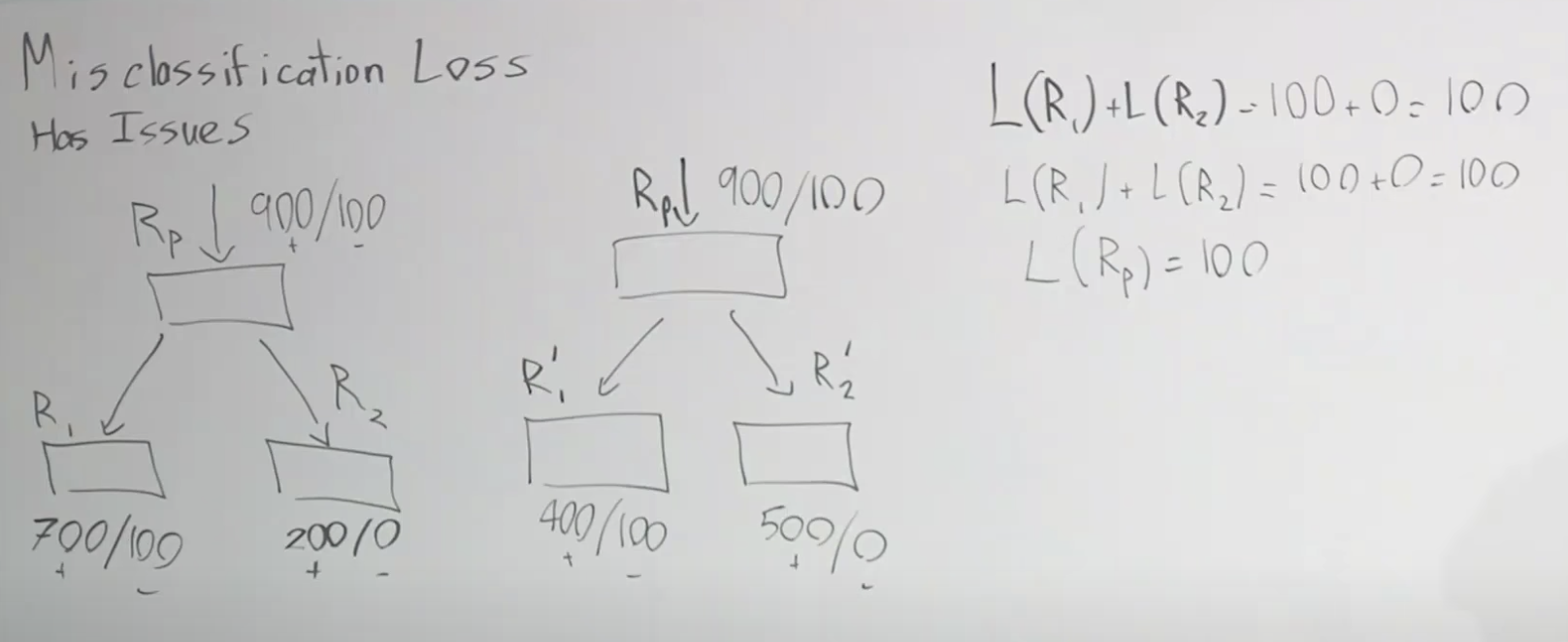
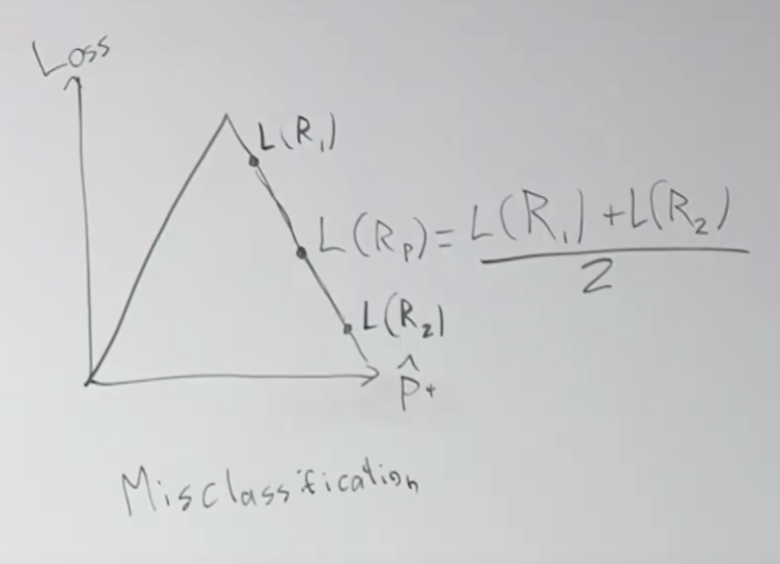
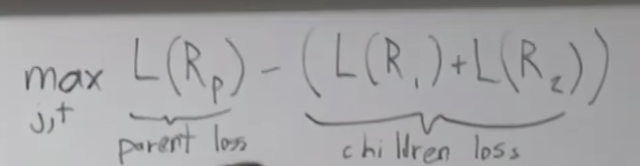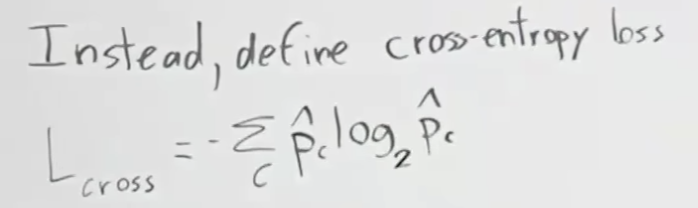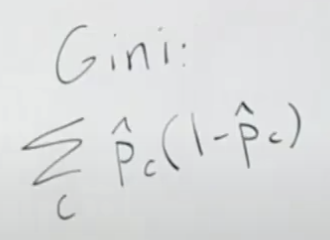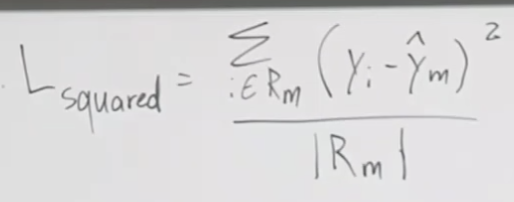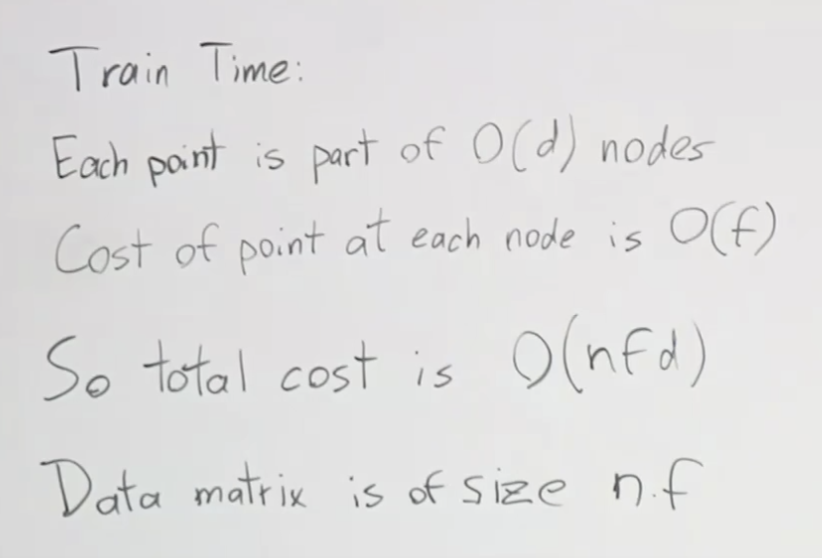주요 내용
- Deep Learning 이란
- Linear Regression 으로 본 신경망
- Neural Networks
Deep Learning 이란
딥러닝은 머신러닝의 한 분야로 특히 컴퓨터비전(CV), 자연어처리(NLP) 등에 많이 사용 되는 알고리즘 입니다. 새로운 처리 방법이지요.
딥러닝이 잘 동작하는 이유는 다음과 같습니다.
새로운 처리 능력의 향상: 첫번째 이유는 계산에 많은 비용이 드는 알고리즘 입니다. 많은 계산이 필요해서 병렬처리하는 것이 필요했는데 GPU가 사용 되었습니다. 많은 계산을 빠르게 처리할 수 있게된 것이지요.
많은 데이터 : 인터넷 활성화에 따른 많은 데이터가 만들어 졌고 이렇게 많은 데이터를 가지고 모델을 만들 수 있게 되었습니다. 딥러닝 모델을 데이터가 다 많으면 많을 수록 더 잘 학습하게 됩니다.
새로운 알고리즘 : 많은 데이터와 새로운 계산 처리 기술을 이용하는 새로운 알고리즘을 만들어 냈습니다.
Logistic Regression 으로 본 신경망
첫번째 목표
지난 시간에 배운 로지스틱 리그리션을 활용해서 신경망을 설명해 보겠습니다. 첫번째 분류 문제로 고양이가 들어있는 이미지를 분류하는 것을 생각해 보겠습니다. 고양이가 있으면 1, 없으면 0을 나타내는 모델을 만들어 봅시다. 컴퓨터 공학에서 이미지를 3차원 행렬로 표현합니다. RGB 3가지 채널이 있기 때문이지요. 가로64픽셀, 세로 64픽셀의 칼라 이미지가 있다면, 가로 64픽셀 X 세로 64픽셀 X 3(RGB) 개의 픽셀 값으로 표현 됩니다. 이 값들을 하나의 벡터로 만들어서 입력 데이터로 사용합니다. 로지스틱 회귀에서의 공식을 적용해보면 아래와 같이 됩니다. 각 입력값 별로 가중치가 필요하니 64 * 64 * 3 개의 w가 필요합니다. 그래서 W의 크기가 (1, 12288)이 되었습니다.

모델을 훈련하는 절차는 다음과 같습니다. i) 먼저 w(가중치), 와 b(바이어스) 를 초기화 합니다. ii) 최적의 w, b를 찾습니다. iii) 찾은 w,b 값을 이용해서 모델을 통해 예측을 실행 합니다. 두번째 단계가 특히 중요한데 여기서 로스(loss)와 Optimizer(Gradient descent) 같은 방법을 사용해서 최적의 w, b를 찾습니다. 로스는 MLE 를 이용해서 구하고 w와 b는 편미분한 값을 빼줌으로서 학습합니다.

여기에 사용되는 파라메터 갯수는 모두 몇개일 까요?
바로 12,288개 + 1개 입니다. 즉, 웨이트 갯수와 바이어스 갯수의 합인 것이지요.
두가지 기억하고 있어야 할 것이 있습니다. 첫째, 뉴런은 리니어 파트와 엑티베이션 파트로 구성된다는 것 입니다. 위의 그림에서 wx + b 부분이 리니어 파트이고 시그마 부분이 엑티베이션 파트 입니다. 동그라미가 바로 뉴런 입니다. 두번째, 모델은 아키텍처와 파라메터라는 것 입니다. 실무에서 모델을 만들어 배포했다는 것은 모델 아키텍처파일과 파라메터 파일을 배포했다는 것이고 이 두 파일을 이용해서 예측을 계산 / 실행하게 됩니다.

두번째 목표
두번째 분류 문제를 생각해 보겠습니다. 이번에는 이미지에서 고양이, 사자 또는 이구아나를 찾는 문제 입니다. 어떻게 할 수 있을까요? 뉴런을 2개 더 만들어서 3개로 할 수 있겠습니다.

그럼 이 모델에서는 몇개의 파라메타가 있을가요? 앞에서 소개한 파라메터 숫자의 3배가 필요합니다.
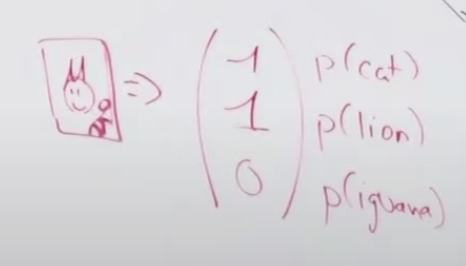
그럼 어떤 데이터가 필요할까요? 네..이미지 데이터와 레이블 데이터 입니다. 이번 문제에서는 고양이, 사자, 이구아나 중에 어떤 동물인지를 표시해야하기 때문에 레이블 데이터가 필요합니다. 1번 이미지는 고양이 이고, 2번 이미지는 사자이고 등등...여기서 고양이, 사자 이런게 레이블 데이터 입니다. 즉, 레이블 데이터이란 훈련 데이터에 해당하는 정답 데이터를 말합니다. 이미지도 숫자로 입력되는 것처럼 출력도 고양이, 사자 이렇게 할 수 없어서 숫자나 위치를 정해야합니다. 이번 문제에서는 아래와 같이 레이블 데이터를 정하겠습니다. 하나의 이미지에 대해서 하나의 벡터 값으로 어떤 동물인지를 표시하는 것 입니다. 예를 들어 첫번째 값이 1이면 고양이를 표시하고, 두번째 값이 1이면 사자, 세번째 값이 1이면 이구아나를 의미합니다.

위와 같은 데이터를 가지고 모델을 훈련할 수 있습니다. w, b를 초기화 시키고 로스를 계산하고 오차를 계산해서 w,b를 변경해 가면서 최적의 모델을 만들 수 있습니다.
이렇게 진행할 경우 그림 3에 제일 위에 있는 첫 번째 뉴런은 무엇을 배울까요? 바로 이미지에 고양이가 있는지 없는지를 학습하게 됩니다. 왜 그럴까요? 바로 아웃풋의 첫번째 위치가 바로 고양이의 존재 여부를 판단하는 내용이고 이 아웃풋이 첫번째 뉴런과 연결되어 있기 때문입니다. 아웃풋 벡터의 순서가 다른 것을 의미한다면, 즉 레이블 데이터가 바뀐다면 각 뉴런에서 학습하는 내용은 바뀌게됩니다.
그럼 이 모델은 여러 개의 동물이 있는 이미지에도 잘 분류할까요? 만약, 고양이와 사자가 들어있는 이미지를 모델에게 준다면 모델은 고양이도 잇고 사자도 있다고 판단할 것입니다. 아래 그림처럼 아웃풋 벡터에서 고양이와 사자에 해당하는 위치의 값이 1로 나올 것 입니다.
로스 계산은 아래와 같습니다. 각 동물별 로스의 합으로 전체 로스를 만듭니다.

세번째 목표
문제 3 세번째는 2번째 문제에서 처럼 두가지 동물을 모두 표시하는 것이 아니라 하나의 이미지에 가장 확실한 동물 한 종류만 표시하고 싶습니다. 어떻게 해야할 까요? 각 동물에 해당하는 출력 값들을 모아서 각 동물의 결과를 나누어 주면 됩니다. 그러면 각 동물별 결과치의 비율이 나오게 됩니다. 각 비율을 모두 합친 값은 1이 되겠지요. 에를 들면 처음 z1, z2, z3 값이 5, 3, 1 이었다면 소프트맥스 함수를 거쳐서 나온 값은 [0.86681333 0.11731043 0.01587624]이 됩니다. 결과 값이 z1이 제일 크네요. 이렇게 만드는 것이 소프트맥스(Softmax) 함수 입니다. 이러한 결과 값과 비교하기 위해 레이블 데이터는 고양이인 경우 [1,0,0], 사자인 경우 [0,1,0], 이구아나인 경우 [0,0,1] 로 등록되야 합니다. 이처럼 소프트맥스 함수를 통해 출력의 분포를 구할 수 있습니다.
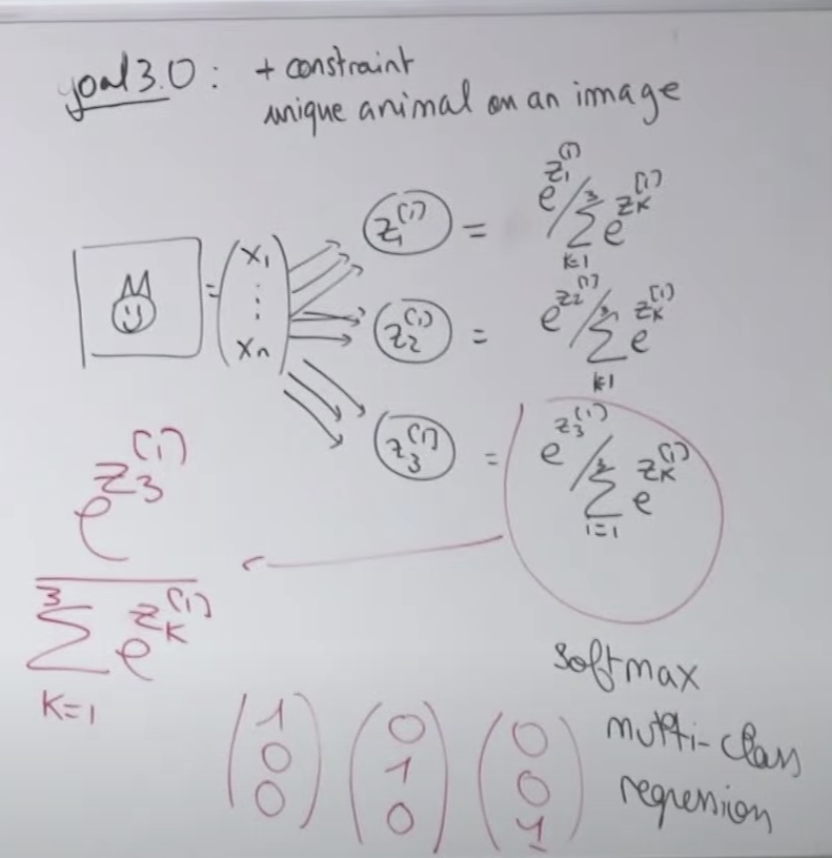
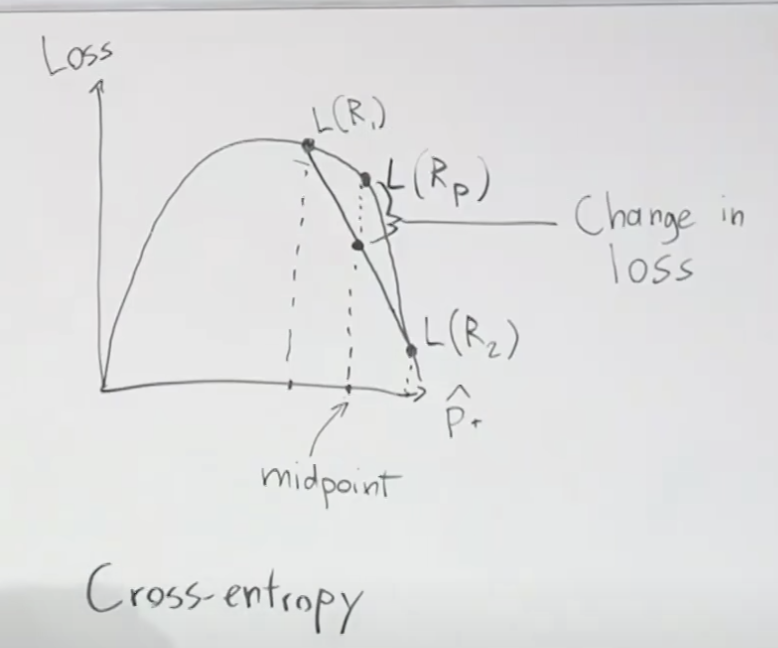
Softmax 함수 계산으로 출력값 z1, z2, z3사이에 서로 영향을 주기 때문에 로스는 크로스엔트로피로스(Cross Entropy Loss)를 이용합니다.

질문입니다. 만약 이미지에서 고양이의 존재를 있고 없고 판단하는게 아니라 고양이의 나이가 얼마가 되는지를 예측하는 문제라면 어떤 네트워크를 사용하시겠습니까? 문제 1을 풀기 위한 그림1 네트워크가 좋을까요?, 문제 2를 플기위한 그림3의 네트워크가 좋을 까요? 아니면 문제 3을 풀기위한 그림5의 네트워크가 좋을까요? 네 문제 3을 풀기위한 그림5 네트워크를 연령대 구분으로 나누어서 사용할 수 있을 것 같습니다. 첫번째는 10대, 두번째는 20대...이런 식으로요...물론 하나의 출력 노드를 가지는 리그레션 모델로 만들 수도 있습니다. 리그레션 모델로 한다면 시그모이드 함수를 사용하지 말아야 겠지요. 그 대신 신경망에서 많이 사용하는 레루 ReLU 함수를 이용하는 것이 좋습니다. 로스함수는 L1 놈/노름( |y^ - y|) 또는 L2 놈/노름(||y^ - y||L^2)를 사용하면 되겠습니다.
Neural Networks
다시 이미지에 고양이가 있는지 없는지를 구분하는 첫번째 문제를 생각해 보겠습니다. 로지스틱 회귀의 신경망 버전에서와 달리 중간에 히든 레이어를 추가할 수 있습니다. 이것은 입력과 출력에서 보이지 않는 신경망 계층을 의미합니다. 신경망의 첫번째 레이어는 단수한 엣지 같은 것을 식별해내고 두번째 레이어에서는 귀나 입 같이 좀더 복잡한 모양을 찾아냅니다. 이처럼 신경망의 깊이가 깊어질 수록 보다 복잡한 구조를 이해하게 됩니다. 파라메터의 갯수는 첫번째 레이어에서 3n + 3, 두번째 2 * 3 + 2, 세번째 2 * 1 +1 개가 됩니다.

이번에는 집가격 예측 모델에 예를 들어 보겠습니다. 사람이 모델링을 한다고 가정하면 방의 갯수, 크기는 가족의 크기와 관련이 있다고 생각할 것입니다. 그리고 우편번호는 이웃과 걸어다닐 만한 거리인지를 알 수 있을 것입니다. 그리고 우편번호와 부유한 정도를 통해 학교의 품질을 알수 있다고 생각할 것입니다. 이렇게 생각해낸 두번째 항목들 즉, 가족의 크기, 걸어다닐 수 있는 정도, 학교 품질이 집의 가격이 정해지는데 더 중요한 요소일 수 있습니다. 사람은 이렇게 컨택스트나 개념을 이용해서 모델링 할 수 있습니다. 그러나 Neural Network은 데이터 간에서 이러한 중요성과 관계를 스스로 학습하게 됩니다.
블랙박스 모델(black box model): 사람은 모델이서 어떤 것을 학습해서 다음 레이어에 전달하고 또 그것이 의미하는 것이 무엇인지 알 수 없기 때문에 딥러닝을 블랙박스 모델이라고 합니다.
엔드투엔드 러닝(end to end learning) : 보통 딥러닝은 입력과 출력을 정의하고 네트워크 모형을 정의한뒤에 데이터를 통해 훈련하는 방법입니다. 즉, 중간에 사람이 개입하여 어떤 작업을 하는 것이 없는 것 입니다. 이러한 방법을 end to end learning 이라고 합니다.



어느 정도 숫자의 노드와 레이어를 만드는 것이 좋을까요? 정답은 없습니다. 두가지 팁을 드리면 첫째 아무도 모르기 때문에 해봐야 합니다. 훈련 데이터를 가지고 여러 개로 나누어서 여러 개의 다른 모델을 훈련해서 어떤 모델이 좋은지 알아보는 방법입니다. 두번째는 문제가 얼마나 복잡하냐에 따라서 달라집니다. 고양이 종을 분리하는게 어려울까요? 아니면 이미지가 밤인지 낮인지 분류하는게 어려울까요? 네...고양이 종을 분류하는게 더 어려울 것 같습니다. 따라서 고양이 종을 분리하는 모델을 만들때 보다 복잡한 많은 레이어와 노드가 있는 네트워크를 만들어야 할깝니다.
Optimizing
먼저 로스 함수를 정의 합니다.

Backward Propagation
Loss 함수를 편미분한 만큼씩 W와 B의 값을 수정해주는 것이 필요합니다. 이것을 모든 레이어 별로 실행해 줘야 합니다. 이때 시작하는 포인트가 Level 3 즉, w3 부터 미분해줍니다. 이렇게 하면 이후에 계산할 w2에서 앞서 계산한 값을 이용할 수 있기 때문에 계산이 쉬워집니다. 그래서 네트워크의 출력단 즉, 뒤에서 부터 계산하게 되는 것이지요.

이상으로 Neural Network에 대해서 알아보았습니다.
아래는 강의 링크 입니다.
https://www.youtube.com/watch?v=MfIjxPh6Pys&list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU&index=11