반응형
빅데이터와 SNS시대의 소셜 경험 전략 - 배성환, 김동환, 곽인호, 송용근 지음
제목과 같이 빅데이터로 인한 사회의 변화, 특히 SNS를 중심으로한 소셜 네트워킹에 의한 사회 변화와 콘텐츠 플랫폼, 마케팅, 비즈니스의 영향과 변화, 그리고 전략에 대한 이야기 이다. 이러한 인사이트를 통해 기업과 조직에서 새로운 고객 경험을 만들려는 제품/서비스 기획자, 마케팅 담당자, 산사업 전략 담당자 등 업무를 수행하는데 도움이 되기를 작가들은 바라고 있다.
그래서 작가들의 직업/경력들도 빅데이터에 대한 기술적인 전문가라기 보다는 경영, MBA, 기술기획, UI/UX디자인 등으로 다양하고 그래서 책을 같이 쓴것 같다.
장점이자 단점으로 많은 영역을 커버하기는하지만 그만큼 한분야에 전문적이거나 상세한 내용을 담지는 못한 것 같은 느낌이다.
그래도 키워드와 전략적 방향성 등은 계속 일관되고 향후에도 지속적으로 중요한 전략방향으로 생각되므로 도움이 될 것 같다.
(소셜을 보는 시각 중에 하나로 새로운 개인 미디어 또는 고객과의 소통 채널의 하나로 생각할 수 있다. )
1장 빅데이터 시대의 새로운 가능성, 소셜 경험
빅데이터는 2012년 10대 전략기술로 [가트너]가 선정했다.
구글에서 검색하면 2012년 7월 기준으로 약 2억 4000만개의 웹문서를 찾을 수 있다.
다른 포스팅에서도 밝혔지만, 생각하기에 통신, IT기술의 발전에 따라 데이터에 처리가 더욱 빠르고 저렴한 비용에서 소통 가능하게 되었으며 이를 이용해 생긴 채널이 바로 SNS로 생각된다. 특히 무선 네트워크의 발달과 스마트폰의 유행은 소셜 시대를 만들어내는 기반이 되었다.
소셜 미디어는 어떻게 데이터를 폭증시키는가에서 아래와 같이 들고 있다.
- 매일 500년 분략의 유튜브 동영상이 페이스북을 통해 시청되고 있다.
- 매분 700개 이상의 유튜브 동영상이 트위터에서 공유된다.
- 300억 개 이상의 누적 트윗이 존재한다.
- 매일 2억 5천만 건 이상의 트윗이 발생한다.
- 페이스북에는 매일 2억장 이상의 사진이 업로드된다.
(출처: 페이스북/유튜브 공식 통계, 테크크런치(http://techcrunch.com) 2011년 10월 기준)
2장 소셜이 만드는 새로운 데이터 세상
빅데이터 시대의 소셜 미디어가 중요한 이유는 바로 개인에 맞는 서비스를 개인에 맞는 방법으로 전달할 수 있기 때문이다.
이러한 사례로 책에서는 2010년 개봉된 페이스북을 다룬 영화 '소셜네트워크'에 대한 국내/해외 포스터의 차이를 보고 소셜미디어를 바라보는 시각이 다름을 예로 들고 있다.
한국에서는 5억명의 사용자가 있다는 성공적인 서비스를 다룬 영화라는 것이 촛점을 맞춘 반면 미국에서는 친구와의 대립 없이 샓게 만들어지기 힘들었던 관계에 주목한다.
이러한 소셜 미디어는 2010년에 일어난 튀니지의 재스민 혁명을 예로 들면서 소셜 미디어의 힘을 설명하고 있다
이러한 소셜 미디어의 데이터는 계속 폭발적으로 증가하고 있으며, 이처럼 넘치는 데이터 안에서 원하는 정보를 찾는 것이 중요해졌음을 설명한다.
손님에게 제공하기 위한 셀러드 준비과정을 데이터 준비과정과 비교하며 설명한다.
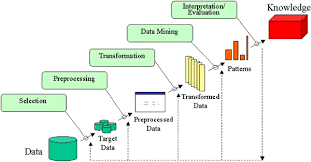
Raw Data (들의 채소 등 제료) -> Data Mining(좋은 재료 선택/발굴) -> Filtering/Preprocessing(채소 손질) -> Analysis(준비한 그릇에 잘 섞어줌) -> Post processing/Visualiztion(드레싱 뿌리기) -> Presentation/Service(접시에 덜어서 서빙) -> 맛을 보면서 행위에 영햐을 줌
마이닝의 두가지 관점 : 긁어 모으는(Crawling)방법과 기록하는(Logging)방법- 즉, 구글과 아마존
기업이 준비해야 할 변화 : 큐레이션
빅데이터 분석에 두드러진 효과를 나타내는 영역은 마케팅
그밖의 활용분야/사례로 구글의 독감 트렌드, 공공기관인 아리조나주의 길버트 앱, 센프란 시스코의 주차 안내 등
3장 소셜 경험 in 사회
선거 당선 예측 : 2011년 서울시장 보궐선거 (박원순, 나경원 후보의 네트워크)
2008년 미국 대선 오바마 후보 케이스
4장 소셜 경험 in 네트워크
네트워크의 힘 : 시계방향이 모두 오른쪽으로 도는 이유
3초 백과 대치동은 어떻게 만들어 졌나? - 왜 3초 백이란 별명처럼 많이 사용하게 되었나? 왜 대치동하면 비싼 동내가 되었나?
이유는 3초 백이니까, 그리고 대치동이니까...ㅋㅋㅋ
강한 네트워크는 강한대로 약한 네트워크는 약한 대로 의미가 있다.
1970년대 사회학자 마크 그라노베터의 주장 : 취직, 결혼 등 사회적인 중요한 전환점에는 깊은 관계보다 약한 연결의 영향이 더 크다는 주장
이유는 강한 연결의 네트워크는 동질성을 갖기 때문에 동일한 관점/행동을 추구할 가능성이 높다. 따라서 챙겨주기 힘들다. (나도 결혼 안했는데.... 나도 취직 안했는데...)
스텐리 밀그렘의 '좁은 세계' 모델에서 봐도 약한 연결은 중요함. 서로 다른 두개이상의 강한 네트워크를 연결해주는 약한 연결이 중요함.
영국의 인류학자 로빈 던바(던바 숫자) : 인간 뇌의 한계로 인해 약 120~200명 정도에서 일반적인 관계를 맺을 수 있다
1960년대 컴퓨터는 인간을 달로 보내는 데 사용되었고, 21세기의 사람들은 새를 날려보내 되지를 잡는 데만 열중하고 있다.
2012년 2월 소셜 미디어 데이터 플렛폼을 표방하는 데이터시프트사가 트위터와 계약해서 약 2년간 트위터의 모든공개 기록들을 판매한다고 발표
소비자가 지갑을 여는 행위는 최고의 기술이나 최저 가격에 의해서만 결정되진 않는다
새로운 경험이 소비를 결정짓게 한다.
5장 소셜 경험 in 콘텐츠 플랫폼
소셜을 통한 경험의 확산 :
- 2011년 베트맨 다크나이트, 페이스북을 통해 제공,
- 케이팝 기획사(YG, JYP, SM)의 전세계 뷰 22억건
- 2011년 10월 유튜브 공개된 소녀시대 '더 보이즈' : 4개월 만에 3천만건
(별도조사)- 2012년 7월 올린 강남스타일 유튜브 조회건수 27억(2017년 2월기준)
TEDx
전 세계 어느 곳이라도 도시나 지명, 혹은 학교의 이름을 붙여서 그 지역에서 연사를 발굴하고 컨퍼런스를 열 수 있는 TED의 라이선스 프로그램이다. 강연 포맷과 TEDx라는 행사이름, 그리고 TED와 동일한 비영리적 행사 운영과 강연 콘텐츠 동여상 무료 공유 등의 가이드라인. TEDx라는 이름으로 수많은 콘텐츠를 확보하게 됨
6장 소셜 경험 in 마케팅
어떻게 이 제품을 추천하게 됐을까? : 최대 매칭(Max Matching) 한사람이 4권의 책을 샀을때 비슷하게 책을 구입한 다른 사람들의 기록과 비교채서 가장 많이 중첩되는 5권중 아직 사지 않은 다섯 번째 책을 추천하는 방식
왜 내게 비싼 가격을 제시했을까? 1990년대 말, 아마존의 메일발송 카탈로그(카탈로그와 온라인 제시 가격이 다름, 카탈로그가 더 비싸게 표시됨)
내 친구의 소식이광고가 되기까지 : 페이스북에서 친구가 좋아요를 누르고 스폰서 페이지에서 행위를 할경우 해당내용이 친구가 좋아요를 눌렀습니다.와 제품을 이용하는 로그를 남긴 것을 본다면 자기도 따라서 하고 싶은 욕구가 생긴다는 것
비즈니스에 직결되는 분석
주목해야할 두 가지 키워드 : 검색과 공유
- 1898년E.S 루이스 : AIDA - Attention Interest Desire Action
- 아키야마 류헤이: AISAS - Search Action Share
휴리스틱 평가 : 사용성의 대가인 제이콥 닐슨이 정의한 것으로 전문가가 웹사이트의 ㅏ숑ㅇ성을 판단할 수 있는 기준이 되는 10가지 조항들을 정리한 것
빅데이터 시대의 소비자들은 구매 의사 결정에 직간접적으로 영향을 주는 다양한 요소들에 대해 네트워크 환경 속에 여러 가지 모습으로 흔적을 남기고 있다. 다양한 분석을 통해 어떻게 활용할지, 어떻게 고객의 구매로 자연스럽게 연결할 수 있을지가 관심의 대상이 되고 있다. 고객들은 자신만의 판단 기준을 갖기 시작했다. 개인적 경험, 주변 평판, 객관적인 진정성 등.
무작위 친절
-진실해야한다.
-개인적이어야 하나 지나치면 안된다.
-온화하게, 하지만 무신경해서는 안된다.
-공유할 수 있게 하라 - 공유해야할 이유를 줘라
-관대하라 - 소수의 사람에게 진정으로 관대하라
-의마와 목적이 있어야한다 - 고객이 활동에 참여하도록 장려하라
-방해하거나, 밀어붙이거나, 판매하려하지 말라
-무작위적 친절 행동을 남발하지 말라.
오늘날 소비자는 현명한 소비를 원한다. - 공정 무역 : 막스 하벨라르(책임소비에 앞장서온 단체), 알린 버트(백그라운드 스토리즈), 유레카 목장
7장 소셜 경험 in 비즈니스
파리의 자전거에서 답을 찾다 ( 벨리브 시스템-서울 따릉이 같은 공공 자전거 대여 서비스)
필립 코들러, 기업의 사회적 참여에 대한 6가지 유형을 제시
1. 특정 사회 문제에 대한 대중의 관심과 기금 모금/자원봉사자 모집 등을 장려하기 위해 기업이 기금, 기타 기업 자산을 제공하는 공익 캠페인(Cause promotion)
2. 공익연계 마케팅(Cause-related marketing) : 회사 매출의 일정 비율을 기부
3. 사회 마케팅(Corporate social marketing) : 개개인의 행동 변화에 초점을 둔 캠페인을 개발 실천하고 지원하는 활동을 의미
4. 사회 공헌(Corporate philanthropy) : 특정 사회문제나 공익사업에 현금/물품, 서비스, 장비, 기술 등을 직접 기부하는 방식
5. 지역사회 자원봉사 활동(Community volunteering)
6. 사회 책임 경영 프랙티스(Socially responsible business practice) : 경영과 투자활동을 통해 환경 보호와 사회 복지 개선에 기여하는 활동
2011년 마이클 포터 는 '하버드비즈니스리뷰'를 통해 '공유 가치의 창출(CSV: Creating Shard Value)라는 개념을 제안
8장 큐레이션 시대의 소셜 경험 전략
행복 확산 캠페인이 증명한 바람직한 소셜 경험 전략
KLM 캠페인 사례: 포스퀘어와 트위터를 활용해 당일 KLM과 관련되거나 관시믕ㄹ 보인 승객을 찾고, 그들이 어떤 성향을 지녔는지 파악해서 그들에게 선물을 전달하는 과정을 포함, 과정을 유튜브 동영상으로 제작 배포.
예상치 못한 친절하에 감동하고 이를 소셜 미디어를 통해 기분 좋은 경험을 다시 공유하는 과정을 통해 고객경험이 홍보됨
40명에게 선물, 1억명이 넘는 트위터 사용자에게 확산, 2011년 KLM은 소셜 브랜드 순위 22위
트위터 프로필 사진과 댓글을 보고 스포츠를 좋아하는 사람인지 알아내고 거기에 맞게 선물 준비(손목시계가 없음을 확인하고 나이키 손목 시계 선물)
비즈니스의 본질은 누가 얼마나 더 고객을 만족시키고 이를 통해 이윤을 창출할 수 있는가에 있다. 소셜/빅데이터는 고객을 더욱 깊이 파악해 좀 더 만족시키기 위한 도구로서 중요한 역할을 할 수 있다는 점에 우리는 주목해야 한다.
반응형
'빅데이터_Big Data ' 카테고리의 다른 글
| 5 - 고객 프로파일링(Customer Profiling) - 기술 구현 관점 (0) | 2017.03.16 |
|---|---|
| 데이터 분석 방법론 (2) - 예시포함 (CRISP-DM) (2) | 2017.02.25 |
| EDW와 빅데이터 아키텍처 (0) | 2017.01.20 |
| 빅데이터 아키텍처란 무엇인가? (0) | 2017.01.10 |
| 데이터 분석 방법론 (KDD, SEMMA, CRISP-DM) (0) | 2017.01.08 |