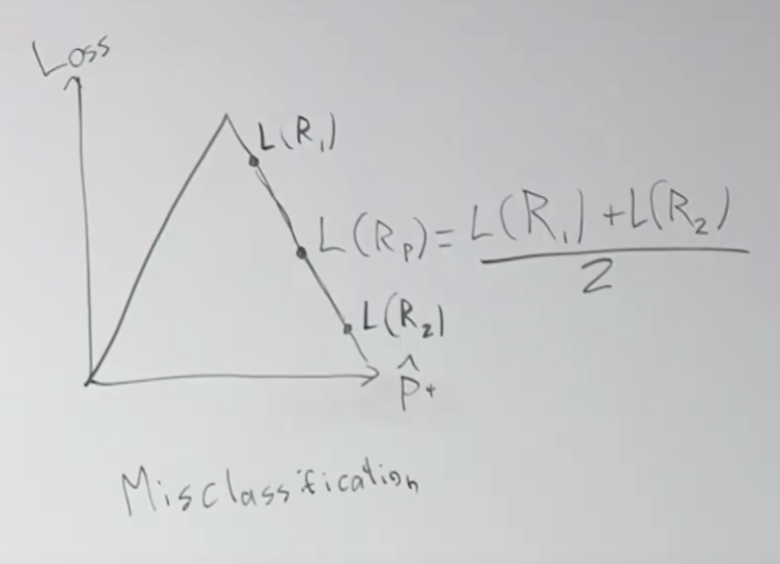
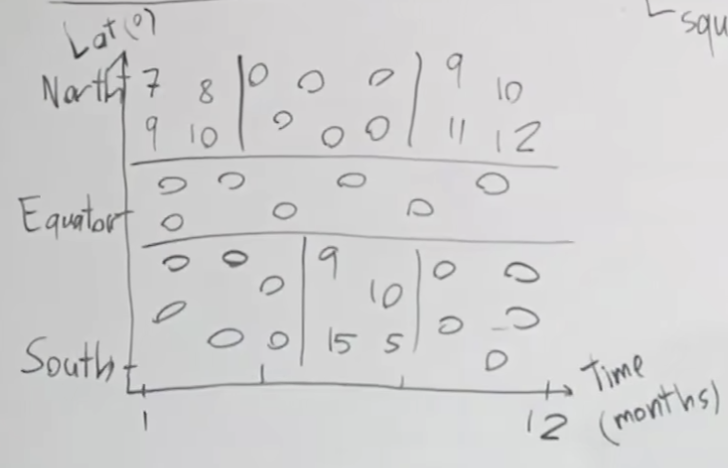
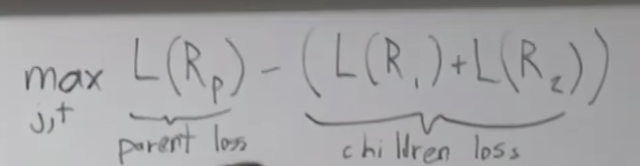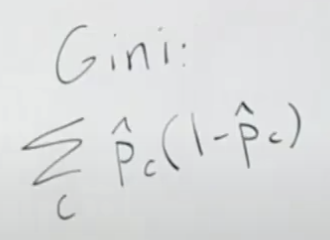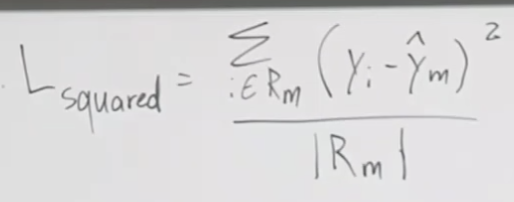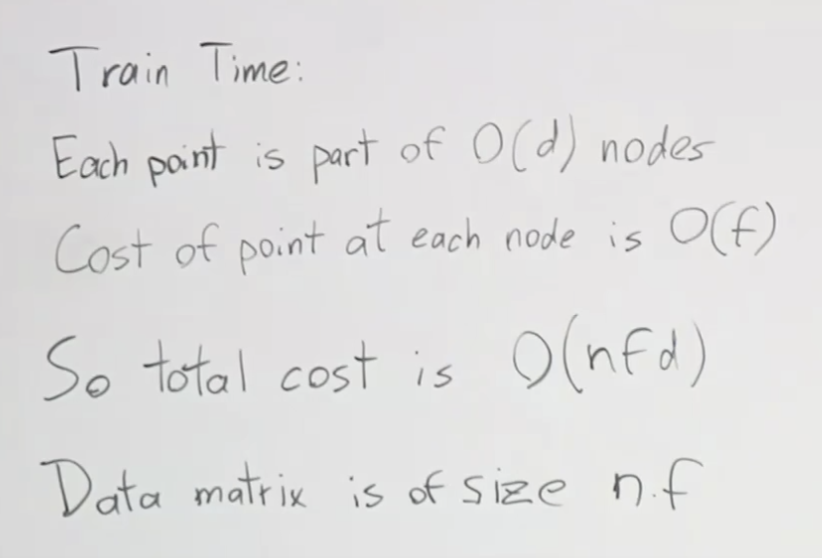Tokenization이란? 토큰화? 토크나이제이션이란?
Tokenization 은 텍스트를 토큰이라고 불리우는 작은 단위로 분리하는 것을 말합니다.
자연어처리 영역에서 토크나이제이션이란 위과 같이 정의할 수 있습니다. 여기에서 텍스트(text)는 문서나 문장 등을 말합니다. 즉, 인터넷 뉴스 기사, 블로그 글, 또는 이메일이나 간단한 채팅 내용 등도 모두 텍스트 데이터 입니다. 텍스트에서 데이터 분석이나 모델 개발 등 특정 목적을 위해 수집된 텍스트 데이터를 코퍼스(Corpus)라고 말합니다. 말뭉치라고 하기도 합니다. 이러한 코퍼스를 데이터 전처리를 통해 Features를 만들게 됩니다. 그 첫 번째 작업이 말뭉치를 토큰이라고 불리우는 더 작은 단위로 나누는 토큰화입니다. 자연어 처리 과정중에서 토큰화의 위치를 설명하는 아래 그림에서 쉽게 이해하실 수 있으실 껍니다.

즉, 텍스트를 잘게 나누는 것을 토큰화라고 할 수 있습니다. 이렇게 잘게 나누는 방법은(토큰은) 보통 3가지가 있습니다. 단어, 서브단어, 문자 입니다. 문장도 가끔 포함됩니다. 코퍼스를 텍스트의 일부라고 했으니 일반적인 경우는 여러 문장이 들어있는 문단 또는 문서가 코퍼스 입니다. 그래서 문단이나 문서는 문장으로 나눌 수 있고, 문장은 다시 단어로 나눌 수 있고, 단어는 문자로 나눌 수 있습니다. 필요에 따라서 이렇게 세분화 하는 것이 토큰화(토크나이제이션, Tokenization)입니다. 토큰화는 데이터 전처리의 한 단계입니다. 토큰화, 정제, 정규화, 불용어 처리, 인코딩 등 여러 단계를 거쳐 실제 모델의 입력 데이터로 사용되는 피처(Features)가 만들어지게 됩니다.
왜 토큰화가 필요한가?
토큰화를 하는 이유는 자연어 처리에서 가장 일반적으로 전처리하는 방법중 하나이기 때문입니다. 가장 일반적인라는 말은 다시 말하면 많은 모델에서 이처럼 토큰화된 데이터를 필요로 한다는 의미 입니다. 실제로 자연어 처리 모델로 많이 사용되는 RNN, GRU, LSTM 등과 같은 신경망 모델들이 토큰화된 데이터를 이용해서 학습합니다.
또다른 이유는 바로 단어 사전을 만들기 위해서 입니다. 코퍼스에서 나오는 데이터를 중복없이 만들어서 모델에서 활용할 일이 많은데 이럴때 바로 토큰화라는 작업을 거쳐서 나온 토큰을 가지고 사전을 만듭니다. 예를 들어 단어로 토큰화를 한다면 단어수가 토큰 수가 되겠네요. 이렇게 만든 사전을 통해 기본적인 토큰의 출현 횟수 라든가, 또는 이런 횟수를 이용한 다양한 분석 방법을 이용할 수 있겠습니다. Word Count(BoW: Bag of Words), TF-IDF 등이 그 예가 되겠습니다.
어떤 토큰화를 해야할까요?
단어 토큰화(Word Tokenization)
가장 일반적인 토큰화 방법은 단어 토큰화 입니다. 특정 구분기호를 가지고 텍스트를 나누는 방법이지요. 영어의 경우 기본적으로는 공백을 구분자로 사용할 수 있습니다. 이러한 방법으로 토큰화하여 사용하는 모델중에 유명한 것이 Word2Vec 과 GloVe입니다. 한글의 경우 교착어라는 특징이 있어서 영어와 달리 구분자나 공백으로 단어 토큰화를 하면 성능이 좋지 않아서 잘 사용하지 않습니다. 한국어는 영어와 달리 조사가 큰 의미를 가지고 있습니다. 조사에 따라 문장내에서의 역할과 기능이 달라지기 때문에 매우 중요한 정보인데 (공백으로 나눈) 어절에서는 조사 정보를 정확히 사용하기 어렵습니다.
단어 토큰화에는 몇가지 안좋은 점이 있습니다. 먼저 OOV 문제가 있습니다. OOV란 Out Of Vocabulary의 약자 입니다. 즉, 입력된 데이터가 이미 만들어져 있던 단어사전에 없는 경우 입니다. 단어 사전은 (토큰의 리스트는) 코퍼스 데이터에서 만들어 지기 때문에 모든 단어를 가지고 있지 않습니다. 그래서 훈련때 없던 단어가 모델 예측 시 입력으로 들어올 수 있습니다. 입력을 받아서 해당 단어/토큰을 찾아서 처리해야하는데 없는거죠. 이 문제의 간단한 해결책은 UNK(Unknown Tocken)을 만드는 것입니다. 훈련 데이터에서 많이 출현하지 않는 단어/토큰을 UNK로 사전에 등록하는 것이지요. OOV문제는 해결할 수 있지만 모든 OOV단어가 같은 (UNK)가 의미하는 표현 값을 갖게 된다는 문제점이 있습니다. 즉, OOV 단어가 많으면 모델이 잘 동작하지 않을 수도 있겠네요. 또 다른 단어 토큰화의 문제는 단어 사전이 클 수 있다는 점 입니다. 사전에 포함된 단어가 많을 수록 사전에서 단어를 찾고 표현을 찾는데 시간이 많이 걸리게 됩니다. 모델의 응답시간에 문제가 생길 수 있다는 의미이고 필요한 경우 고용량의 메모리가 있는 서버 컴퓨팅 자원이 필요하다는 의미 입니다. 이러한 OOV 문제를 해결하는 방법중 하나가 문자 토큰화 입니다.
문자 토큰화(Character Tokenization)
문자 토큰화는 코퍼스를 문자로 분리하는 것입니다. 영어 같은 경우는 알파벳 26개 로 하나씩 분리하는 것이고, 한글의 경우 자음과 모음으로 분리하는 것입니다. 예를 들면 영어의 경우 'Tokenization' 을 T-o-k-e-n-i-z-a-t-i-o-n 으로 분리하는 것 입니다. 한글의 경우에는 "토큰화"를 ㅌ-ㅗ-ㅋ-ㅡ-ㄴ-ㅎ-ㅗ-ㅏ 로 분리하는 것 입니다. 이렇게 하면 단어 토큰화에서 있었던 OOV 문제가 해결됩니다. 모든 텍스트를 분리하면 결국 하나하나의 문자로 분리되기 때문에 모든 문자(영어 26개, 한글 자음/모음)를 사전에 등록해 놓으면 OOV 문제는 해결 됩니다. 그리고 메모리 문제도 해결됩니다. 왜냐하면, 영어 26개 알파벳이나 한글 자음/모음과 각가의 표현에 필요한 정보만 메모리에 저장하면 되기 때문에 메모리 문제도 없어집니다. 그런데 문자 토큰화에도 단점이 있으니, 바로 한 건의 입력 내용이 길어진다는 것입니다. 바로 위의 예에서도 볼 수 있듯이 "토큰화"를 ㅌ-ㅗ-ㅋ-ㅡ-ㄴ-ㅎ-ㅗ-ㅏ로 입력해야 합니다. 하나의 단어 인데도 이렇게 표현이 길지는데 문장이면 더 길어지겠지요. 이렇게 됨으로써 결국 단어와 단어 사이의 거리가 더 멀어지게 됩니다. RNN, LSTM 등 신경망 모델은 하나의 문장/텍스트에 해당하는 토큰 리스트를 순차적으로 입력 받습니다. 그런데 하나의 입력 길이가 길어지면 모델이 단어간의 관계를 학습하는 것을 어렵게 만듭니다. 이러한 문제점은 새로운 토큰화 방법이 필요함을 알 수 있습니다.
서브 단어 토큰화(Subword Tokenization)
서브 단어 토큰화는 문자 토큰화의 확장 버전 입니다. n개의 문자(n-gram characters)를 가지고 나누는 방법입니다. 서브 워드를 만드는 알고리즘 중에서 가장 유명한 것이 BPE(Byte Pair Encoding)입니다. 앞서 이야기한 단어 토큰화는 영어에는 잘 동작하는 편이지만 한국어에서는 잘 안된다고 말씀드렸는데요. 한국어는 형태소 분절 기반의 서브 단어 토큰화가 좋은 성능을 보여서 많이 사용됩니다. 문장을 형태소로 나누어서 각 형태소 별로 인코딩을 하는 방법입니다.
파이썬을 이용한 한글 토큰화
한글 텍스트 "나는 자연어처리와 파이썬을 정말 정말 좋아합니다." 라는 문장을 형태소 분석을 통해 토큰화를 해보겠습니다. 꼬꼬마 분석기를 이용했으며 코드와 설명은 아래와 같습니다.
# 필요한 페키지를 가져옵니다.
from konlpy.tag import Kkma
# 프로그램에서 사용하기 위한 인스턴스를 만듭니다.
kkma = Kkma()
# 텍스트 데이터를 설정 합니다.
sentence = "나는 자연어처리와 파이썬을 정말 정말 좋아합니다."
# 형태소분석 POS(Part Of Speech)를 실행합니다.
results_of_pos = kkma.pos(sentence)
# 결과를 출력해 봅니다.
print(results_of_pos)
출력 결과
[('나', 'NP'), ('는', 'JX'), ('자연어', 'NNG'), ('처리', 'NNG'), ('와', 'JKM'), ('파이', 'NNG'), ('썰', 'VV'), ('ㄴ', 'ETD'), ('을', 'NNG'), ('정말', 'MAG'), ('정말', 'MAG'), ('좋아하', 'VV'), ('ㅂ니다', 'EFN'), ('.', 'SF')]
리스트 안에 튜플의 형태로 정리되어 결과가 나옵니다. 튜플의 첫번째 내용은 텍스트 내용이고 두번째 내용은 품사의 종류입니다. 예를 들면 ('나', 'NP')는 문장내 '나'를 분리해 냈으며 품사는 'NP' 대명사로 판단했습니다. 꼬꼬마 형태소 분석기에 대한 품사 태그표는 여기를 참고해 주세요.
요약
이번에는 먼저 토큰화의 정의를 살펴보았습니다. 토큰화란 텍스트/코퍼스를 작은 단위의 토큰으로 나누는 방법이라고 정의 했습니다. 토큰화 방법에는 단어, 문자, 서브단어가 있고 각각의 장점/단점을 알아보았습니다. 마지막으로는 파이썬 언어를 이용하여 한글을 토큰화하는 사례를 살펴보았습니다. 토큰화를 거처 생성된 토큰 들은 정재, 정규화, 불용어 처리, 인코딩 등의 피처 엔지니어링(Feature Engineering) 단계를 거쳐서 모델의 인풋으로 사용될 피처(Features)로 만들어 집니다. 이러한 단계를 거쳐서 워드 클라우드, 자동 번역, 질의 응답(QnA) 등 다양한 자연어 처리 모델과 어플리케이션을 만들 수 있습니다.
'인공지능-기계학습 > 언어인지_NLP' 카테고리의 다른 글
| 검색에 날개를 달자!!! WebChatGPT (1) | 2023.11.25 |
|---|---|
| 원 핫 인코딩? One-Hot Encoding? (0) | 2022.04.24 |
| TF-IDF tfidf (0) | 2022.03.17 |
| BoW : Bag of Words (0) | 2022.03.15 |
| NLP: Natural Language Processing 자연어 처리 (0) | 2022.03.05 |