Lecture 13 - Debugging ML Models and Error Analysis | Stanford CS229: Machine Learning (Autumn 2018)
이번 강의의 주요 내용입니다.

오늘은 잘 동작하는 학습 알고리즘을 만들기 위한 조언에 대해 이야기 합니다.
오늘 자료는 깊이있는 수학적 내용은 아닙니다. 그러나 이번 수업에서 어찌보면 가장 이해하기 어려운 내용 중에 하나입니다. 과학과 예술 사이의 문제라고 할 수 있습니다. 어떤 사람들은 완전히 새로운 영역의 혁신적인 기계학습 연구를 할 때 이러한 조언들은 오히려 안 좋은 것이라고 말합니다. 그러나 기존에 연구된 유사한 문제를 유사한 방법으로 풀기위해서는 많이 도움되는 좋은 조언이라고 할 수 있습니다. 주요한 내용/아이디어는 다음과 같습니다. 1. 학습알고리즘을 디버깅하기 위한 진단방법은 무엇인가. 2. 에러 분석과 제거 분석은 무엇인가. 3. 기계학습 문제에서 통계적 최적화를 어떻게 시작할 것인가.
1. 학습알고리즘을 디버깅하기위한 진단방법은 무엇인가?

스팸 메일을 막기위한 Anti-spam 모델을 만든다고 가정해 보겠습니다. 모든 영어 단어를 피처로 이용하는 대신에 100개의 단어를 피처로 골랐습니다. 로지스틱 회귀와 경사 상향법을 가지고 모델을 구현하였습니다. 그래서 20%의 테스트 에러가 발생했는데 이것은 쓸수 있는 수준이 아닙니다. 자 이런 상황에서 여러분이라면 무엇을 하시겠습니까?

가장 기본적이고 효과적인 진단 방법은 바이어스/베리언스(bias vs. variance) 분석입니다. 무엇이 문제인지를 진단하고 그 문제를 고치는 방법입니다. 보통 모델의 성능이 좋지 않다고 하면 오버피팅이나 언더피팅일 경우입닌다. 오버피팅은 variance가 높은 경우를 말합니다. 반대로 언더피팅은 bias가 높은 경우를 말합니다. 예를 들면 스팸을 분류하기위해서 너무 작은 수의 피처가 사용되면 bias가 클 확률이 높아집니다. 이처럼 모델의 성능의 안정성을 진단하는 방법중 하나가 바로 variance와 bias를 알아보는 것입니다. variance가 큰 경우는 훈련 에러가 테스트 에러보다 훨씬 작은 경우에 발생 합니다. 즉, 훈련에서는 잘 맞추는데 테스트에서는 못 맞추는 경우 입니다. Bias가 큰 경우는 훈련 에러와 테스트 에러가 모두 높은 경우 입니다. 아무리 훈련해도 에러를 줄이지 못하는 상황이 많습니다.

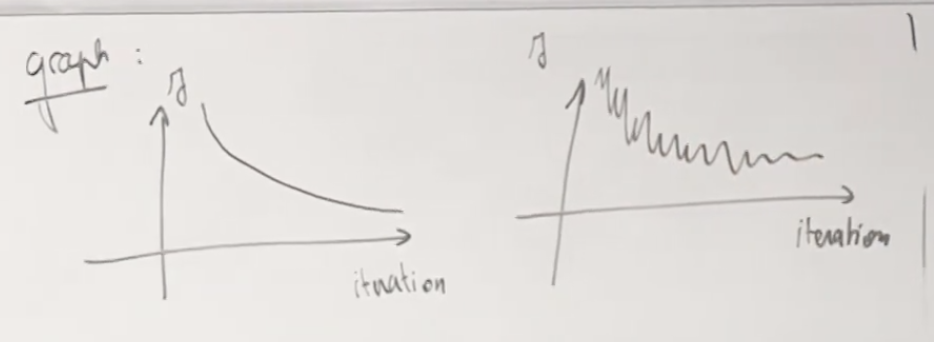
높은 variance를 가지는 모델의 에러와 데이터 량을 그래프로 그려보면 아래와 같습니다. 데이터 수가 많아져도 훈련 에러율과 테스트 에러율의 차이가 계속 발생하고, 훈련 때는 원하는 에러율보다 낮지만 테스트 할때는 높습니다. 그리고 테스트에서는 원하는 목표 에러율보다 낮아지지 않습니다. 목표에러와 테스트 에러의 차이가 많이 난다는 의미입니다. 데이터(m)가 늘어 남에 따라서 테스트 에러율이 낮아지고 있으므로 더 많은 데이터가 도움이 될 것 입니다. 그럼에도 불구하고 훈련 에러율과 테스트 에러율 사이에 차이가 있습니다. 높은 Variance가 있을 경우 아래와 같은 그래프를 보입니다.

다음은 높은 bias를 가진 러닝 커브의 예를 들어 보겠습니다. 높은 바이어스가 있는 경우 훈련 에러와 테스트 에러는 데이터가 많아 짐에 따라서 비슷해지지만, 심지어 훈련 에러율도 원하는 에러율 보다 않좋게 나오는 경우 입니다. 훈련이 잘 안되는 거죠. 이런 경우에는 아무리 많은 데이터 사례를 더 모아서 훈련해도 원한는 모델을 만들 수 없습니다.

Bias-variance is the single most powerful tool for analyzing the performance of a learning algorithm.
guess some problems and find out whether the model has the problems or not.

일반적으로 많이 연구되지 않은 새로운 영역의 모델을 만들때 추천하는 방법은 먼저 지저분한 코드라도 빠르게(Quick and dirty code) 만들어서 돌려보고 Bias/Variance 진단을 해보는 것입니다.
앞서 살펴본 Bias / Variance 문제가 가장 흔하고 가장 중요한 진단 방법입니다. 그밖의 다른 문제에 대해서는 무엇이 잘못된 것인지를 알아내기 위한 당신의 진당방법을 만들기위한 당신의 창의성에 달려있습니다. 다른 예를 들어 보겠습니다. 로지스틱 회귀 모델을 통해 스팸 메일에 대해 2%의 에러율과 정상 메일에 대해 2%의 에러율을 얻었다고 합시다. 실제로 사용하기 어려운/받아들이기 힘든 수준입니다. 또 다른 성형 커널 기반의 SVM 모델을 이용해서 스팸 메일에 대해서 10%의 에러율을, 정상 메일에 대해서 0.01%의 에러율을 얻었습니다. 이정도 성능은 받아들일만 하다고 하겠습니다. 그런데 당신은 계산의 효율성을 위해서 로지스틱 회귀 모델을 사용하기를 원합니다. 어떻게 해야할 까요?

다른 일반적인 질문중 하나는 '알고리즘이 수렴하고 있는가?' 입니다. 오브젝티브 함수를 지켜봄으로써 알고리즘이 수렴하고 있는지를 말하기 어려운 경우가 종종 있습니다. 일반적으로 훈련 반복을 늘리면 오브젝티브 함수는 조금씩 올라가게 됩니다. 그런데 얼마나 더 많은 반복을 해야할까요? 더 많은 반복이 효과적일지 아닌지 어떻게 알까요? 보다 체계적인 방법이 없을까요?

아마도 무엇이 잘 못 되었는지 생각해 본다면 다음과 같은 질문을 할 수 있습니다. 최적화를 위해 올바른 함수를 사용하고 있는가? , 로지스틱 회귀가 맞나? 학습률은 적절한가? 등이 그것 입니다.

SVM은 보통 로지스틱 회귀를 능가하는 성능을 보입니다. 그러나 여러분은 어플리케이션을 위해서 로지스틱 회귀 모델의 배포를 원하는 상황입니다. SVM의 성능이 BLR을 능가함으로, 가중치를 적용한 SVM과 BLR의 정확도를 비교하면 a(θ SVM)이 더 커야 합니다.

BLR 베이지안 선형회귀 (위키피디아)
In statistics, Bayesian linear regression is an approach to linear regression in which the statistical analysis is undertaken within the context of Bayesian inference. When the regression model has errors that have a normal distribution, and if a particular form of prior distribution is assumed, explicit results are available for the posterior probability distributions of the model's parameters.
https://en.wikipedia.org/wiki/Bayesian_linear_regression
Bayesian linear regression - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search Method of statistical analysis In statistics, Bayesian linear regression is an approach to linear regression in which the statistical analysis is undertaken within the context of Bayes
en.wikipedia.org
베이지안 회귀 분석 https://mons1220.tistory.com/212
[통계] 베이지안 회귀분석
회귀는 데이터로부터 모델을 추정하는 한 방법이다. 최소자승법이 잔차를 최소화 시키는 방법이라면, 베이지안 회귀는 가능도 최대화가 목적이다. 이 글의 최종 목표는 베이지안 회귀의 원
mons1220.tistory.com
먼저 최적화 알고리즘의 문제가 있으면 경사하강법은 수렴하지 않을 수 있습니다. 두번째로 잘못된 비용함수를 이용하면 학습되지 않을 수 있습니다.
즉, 진단해야할 것은
1. 옵디마이징 알고리즘이 잘못되서 수렴하지 못하는 건지
2. 아니면 비용함수를 잘못 만든 것인지
확인이 필요합니다.
로지스틱 회귀가 최대화 하려는 비용함수를 확인해볼 필요가 있습니다.
이를 위한 진단 방법은 아래와 같습니다. 앞서본 정확도 a(θ)와 비용함수 J(θ)를 가지고 무엇이 잘못된 것인지 진단 할 수 있습니다.

케이스1 의 경우는 최적화 알고리즘에 문제가 있는 경우이고, 케이스2의 경우는 비용함수가 문제인 경우입니다.

그래서 앞서 살펴 봤던 여러 개선 방법들 중에서 최적화 알고리즘의 문제를 해결하기 위한 방법들과 비용함수 문제를 해결하기 위한 방법들이 아래와 같이 매칭 됩니다.

SVM을 시도하는 것도 오브젝티브 함수를 최적화 하는 것을 고치기 위한 방법중 하나 입니다.
Debugging an RL algorithm
강화학습에 대한 상세 내용은 별도로 정리하겠습니다.



Error Analysis
일반적인 얼굴인식 시스템의 절차는 다음과 같습니다.

원본 사진에서 배경을 지우고

얼굴을 찾고

얼굴에서 눈, 코, 입을 찾고

모델(로지스틱 회귀)을 실행시켜서 최종 아웃풋 레이블을 만듭니다.

전체적인 플로우는 다음과 같습니다.

따라서 각각의 단계 / 모듈이 오류율을 어떻게 변화하는지를 확인할 수 있습니다.
Ablative analysis
Ablative analysis는 각 콤포넌트가 최종 성능에 각각 얼마나 기여했는지를 측정하는 방법입니다. 좋은 피처들이 없는 단순 선형 회귀 모델을 통해서 94%의 성능이 나오고 콤퍼넌트를 추가했을 때 99.9%로 모델 성능이 향상 된 것을 어떻게 설명할 것인가? 라는 질문에 대답할 수 있는 방법이 Ablative analysis입니다. 즉, 기본 베이스 라인 모델(94%)에서 시작해서 하나씩 콤퍼넌트가 추가될때 마다 성능(Accuracy)이 어떻게 변하는지 확인하는 방법입니다. 이런 Ablative analysis를 통해서 어떤 콤퍼넌트가 성능향상에 가장 기여를 많이 하는지 알수 있습니다.

아래는 강의 동영상 링크 입니다.
https://www.youtube.com/watch?v=ORrStCArmP4