얼굴인식, 얼굴인증 등 얼굴관련 인공지능 모델 개발에 필요한 데이터 셋 들의 리스트입니다. 인공지능, 특히 딥러닝을 통한 모델 개발시 유용하게 사용될수 있습니다.
http://vis-www.cs.umass.edu/lfw/#resources
LFW Face Database : Main
vis-www.cs.umass.edu
http://shuoyang1213.me/WIDERFACE/
WIDER FACE: A Face Detection Benchmark
News 2017-03-31 The new version of evaluation code and validation resultsis released. 2017-03-31 Add text version ground truth and fix rounding problem of bounding box annotations. 2016-08-19 Two new algorithms are added into leader-board. 2016-04-17 The f
shuoyang1213.me
1| Flickr-Faces-HQ Dataset (FFHQ)

CELEBA-HQ데이터셋 보다 연령, 민족, 그리고 배경에서 더 다양한 이미지를 가지고 있음. 그리고 안경, 선그라스, 모자 등 악세사리 의 경우에도 더 많은 것을 커버함. Flicker로 부터 수집되어 자동으로 편집된 이미지.
Size: The dataset consists of 70,000 high-quality PNG images at 1024×1024 resolution and contains considerable variation in terms of age, ethnicity and image background.
Projects: This dataset was originally created as a benchmark for generative adversarial networks (GAN).
Publication Year: 2019
Download here.
2| Tufts-Face-Database

일반 이미지, 적외선이미지, 비디오 3D 등 다양함
Size: The dataset contains over 10,000 images, where 74 females and 38 males from more than 15 countries with an age range between 4 to 70 years old are included.
Projects: This database will be available to researchers worldwide in order to benchmark facial recognition algorithms for sketches, thermal, NIR, 3D face recognition and heterogamous face recognition.
Publication Year: 2019
Download here.
3| Real and Fake Face Detection
진짜/가짜 얼굴 데이터

Size: The size of the dataset is 215MB
Projects: This dataset can be used to discriminate real and fake images.
Publication Year: 2019
Download here.
4| Google Facial Expression Comparison Dataset
얼굴 표정 데이타 This dataset by Google is a large-scale facial expression dataset that consists of face image triplets along with human annotations that specify, which two faces in each triplet form the most similar pair in terms of facial expression.
Size: The size of the dataset is 200MB, which includes 500K triplets and 156K face images.
Projects: The dataset is intended to aid researchers working on topics related to facial expression analysis such as expression-based image retrieval, expression-based photo album summarisation, emotion classification, expression synthesis, etc.
Publication Year: 2018
Download here.
5| Face Images With Marked Landmark Points

Face Images with Marked Landmark Points is a Kaggle dataset to predict keypoint positions on face images.
Size: The size of the dataset is 497MP and contains 7049 facial images and up to 15 key points marked on them.
Projects: This dataset can be used as a building block in several applications, such as tracking faces in images and video, analysing facial expressions, detecting dysmorphic facial signs for medical diagnosis and biometrics or facial recognition.
Publication Year: 2018
Download here.
6| Labelled Faces in the Wild Home (LFW) Dataset
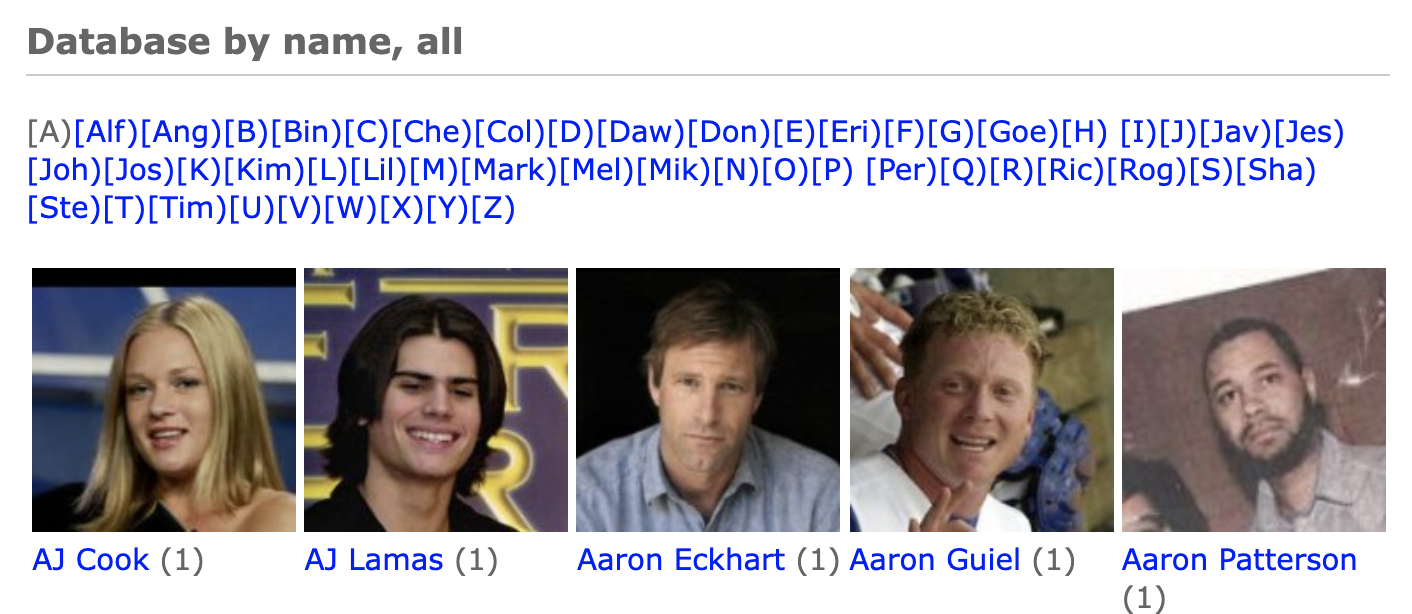
얼굴과 이름이 정의된 데이터, 얼굴인식과 얼굴인증을 위한 데이터셋
Size: The size of the dataset is 173MB and it consists of over 13,000 images of faces collected from the web.
Projects: The dataset can be used for face verification and other forms of face recognition.
Publication Year: 2018
Download here.
7| UTKFace Large Scale Face Dataset
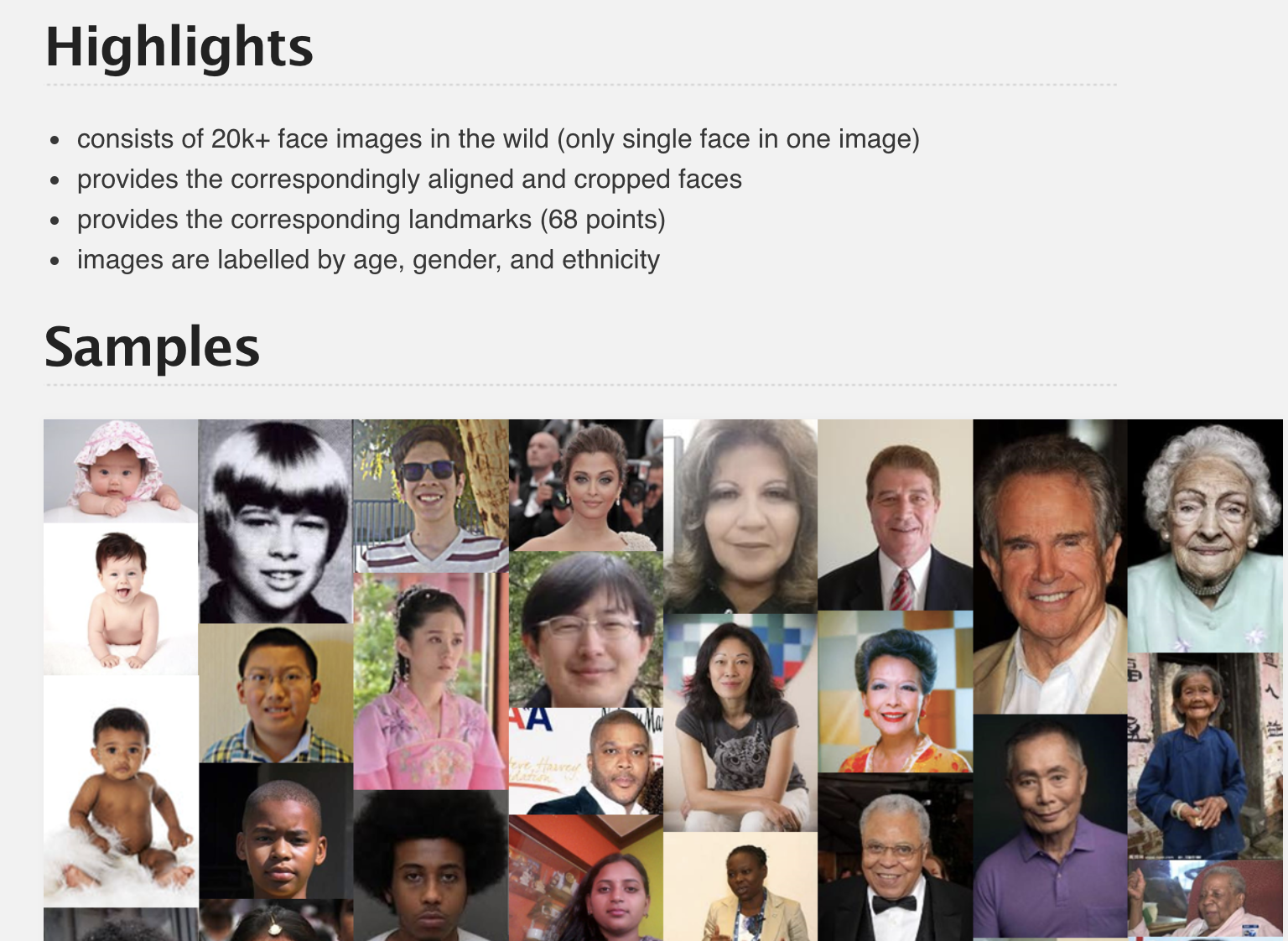
UTKFace dataset is a large-scale face dataset with long age span, which ranges from 0 to 116 years old. The images cover large variation in pose, facial expression, illumination, occlusion, resolution and other such.
Size: The dataset consists of over 20K images with annotations of age, gender and ethnicity.
Projects: The dataset can be used on a variety of task such as facial detection, age estimation, age progression, age regression, landmark localisation, etc.
Publication Year: 2017
Download here.
8| YouTube Faces Dataset with Facial Keypoints

This dataset is a processed version of the YouTube Faces Dataset, that basically contained short videos of celebrities that are publicly available and were downloaded from YouTube. There are multiple videos of each celebrity (up to 6 videos per celebrity).
Size: The size of the dataset is 10GB, and it includes approximately 1293 videos with consecutive frames of up to 240 frames for each original video. The overall single image frames are a total of 155,560 images.
Projects: This dataset can be used to recognising faces in unconstrained videos.
Publication Year: 2017
Download here.
9| Large-scale CelebFaces Attributes (CelebA) Dataset

CelebFaces Attributes Dataset (CelebA) is a large-scale face attributes dataset with more than 200K celebrity images, each with 40 attribute annotations. The images in this dataset cover large pose variations and background clutter.
Size: The size of the dataset is 200K, which includes 10,177 number of identities, 202,599 number of face images, and 5 landmark locations, 40 binary attributes annotations per image.
Projects: The dataset can be employed as training and testing sets for the following computer vision tasks: face attribute recognition, face detection, landmark (or facial part) localisation, and face editing & synthesis.
Publication Year: 2015
Download here.
10| Yale Face Database

15명의 증명사진 같은 이미지, 인당 11장, 다양한 얼굴표현
Size: The size of the dataset is 6.4MB and contains 5760 single light source images of 10 subjects each seen under 576 viewing conditions.
Projects: The dataset can be used for facial recognition, doppelganger list comparison, etc.
Publication Year: 2001
Download here
10개 데이터셋에 대한 원본 글(https://analyticsindiamag.com/10-face-datasets-to-start-facial-recognition-projects/)