지난 포스팅에서는 인공지능/기계학습에 대한 기본적인 정의와 이해에 대해서 알아보았습니다. 학습방법에 따라 지도 학습, 비지도 학습, 강화 학습으로 나눌 수 있다고 말씀드렸었습니다.
https://bigdatamaster.tistory.com/108?category=990312
인공지능 기계학습 용어 상식 - 지도학습/비지도학습/강화학습
인공지능 쉽게말하면, 말 그대로 인공적인 지능을 말한다. 지능이란 인간이 지니는 지적인 능력으로, 합리적으로 생각하고 처리하는 능력이라고 할 수 있다. 인간이 가지는 특징인 지능을 인공
bigdatamaster.tistory.com
이번에는 가벼운 마음으로 인공지능의 역사와 연구분야에 대해 알아 보고자 합니다. 결론부터 말씀드려보면, 인공지능이 처음부터 인기가 많았던 것은 아니었지만 혁신적인 기술과 노력으로 인해 전환점이 되는 계기가 있었습니다. 연구분야의 경우 여러 가지의 방법으로 나눌 수 있겠지만 보통 시각인지 분야(Computer Vision/Multimedia), 언어인지 분야(Natural Language Processing), 그리고 음성/신호 처리 분야로 나눌 수 있을 것 같습니다. 먼저 개괄적인 내용과 인공지능의 역사, 그리고 학회를 통해 알아본 연구분야를 살펴보겠습니다. 이러한 역사와 연구 분야를 알아봄으로써 배경지식을 넓히고 이를 통해 인공지능과 기계학습을 사용할 수 있는 영역을 찾는데 도움이 되길 바랍니다. 물론 창의력을 발휘하여 새로운 영역은 언제든지 만들 수 있습니다. 다만 조금 어려울 뿐이지요.
인공지능 혁신의 시작
인공지능은 1940년대부터 연구된 분야이고 중간에 많은 우여 곡절도 있었고 기호 처리, 전문가 시스템 등 꼭 신경망이 아니라도 다른 여러 가지의 방법으로 인공지능을 만들기 위해 연구해 왔습니다. (너무 내용이 많아서 이 내용은 별도로 이야기하겠습니다.) 현재 우리가 보고 있는 인공지능 혁신의 시작점은 2012년 AlexNet이라는 모델과 2015년 ResNet이라는 모델이라고 할 수 있겠습니다.
먼저 최근 인공지능관련 연구에서 빼놓을 수 없는 분들이 있습니다. 그들은 2018년 튜링 어워드를 수상한 제프리 힌튼(Geoffrey Hinton), 얀 르쿤(Yann LeCun), 조슈아 벤지오(Yoshua Bengio) 입니다. AlexNet은 바로 제프리 힌튼 교수님이 쓴 "ImageNet classification with deep convolutional neural networks" 논문에서 2012년에 발표된 모델입니다. 이 모델이 놀라웠던 이유는 먼저, 기존에 사용되던 모델과 비교해서 우수한 성능 향상을 가져왔다는 것과 또 하나는 신경망의 특징을 찾아냈다는 것일 것 같습니다. 성능은 기존 모델 대비 10.8%의 에러를 줄였고 신경망의 깊이가 깊을수록 좋은 성능을 낼 수 있다는 것을 밝혀냈습니다. 깊은 학습(Deep Learning)을 발견한 것이지요. 그리고 기술적으로는 처음은 아니지만 GPU의 사용과, 얀 르쿤 교수님이 제안한 역전파(Backpropagation) 알고리즘, Max-pooling, ReLU 등을 이용했습니다.
2015년에 ResNet은 더 놀라운 성과를 이루어 냅니다. 바로 사람보다 이미지 분류를 더 잘해 낸 것이지요. 사람은 5%의 에러로 분류했는데 ResNet 모델은 3.57%의 에러로 분류했습니다. 그러니 많은 사람들이 놀랄 수 밖에 없었지요. 그래서 이후에 많은 사람들에게 관심을 받기 시작했습니다. 기술적으로는 말 그대로 딥~네트워크(무려 152층의 신경망 네트워크)를 만들었습니다. 그리고 스킵 컨넥션(Skip-connection), ReLU, Batch normalization을 적용했습니다.
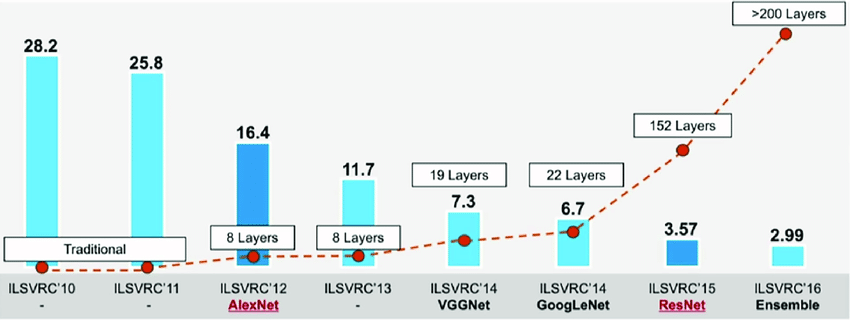
ImageNet Large Scale Visual Recognition Challenge (ILSVRC)
이미지 데이터를 가지고 모델을 학습시켜서 이미지 내 물체를 분류해내고 위치를 찾는 문제를 위한 모델 성능을 평가하는 챌린지
이후로 딥러닝이 여러 분야와 문제에 적용되면서, 그리고 새로운 기술이 적용되면서 많은 확산이 이루어졌습니다. 더불어, 2016년 다보스포럼에서 클라우스 슈바프가 4차산업혁명의 핵심 기술로서 인공지능을 발표하여 세계 많은 사람들의 관심을 증가시켰고, 2016년 3월에는 딥마인드에서 개발한 알파고와 이세돌 기사의 대국으로 인해 국내에서는 더 많은 관심과 주목을 받았습니다. 그래서 더욱 많은 사람들이 인공지능에 대해서 생각하게 되었고 정부나 학계, 그리고 기업에서도 지원을 늘리기 시작했습니다. 현재에는 대학과 기업의 많은 연구소에서 많은 사람들이 많은 연구분야에 대해 활발하게 연구하고 있습니다.
인공지능 연구분야와 지능
인공지능이 해결하고자하는 문제나 연구분야를 고민하기 전에 일반적인 사람의 지능을 어떻게 나눌 수 있는지 생각해보면 좋을 것 같습니다. 인공지능 연구가 지능 연구와 비슷할 수 있으니까요. 위키에서는 지능을 아래와 같이 말하고 있습니다.
지능(智能) 또는 인텔리전스(영어: intelligence)는 인간의 지적 능력을 말한다. 지능은 심리학적으로 새로운 대상이나 상황에 부딪혀 그 의미를 이해하고 합리적인 적응 방법을 알아내는 지적 활동의 능력으로 정의할 수 있다.[1]
지능 - 위키백과, 우리 모두의 백과사전
지능(智能) 또는 인텔리전스(영어: intelligence)는 인간의 지적 능력을 말한다. 지능은 심리학적으로 새로운 대상이나 상황에 부딪혀 그 의미를 이해하고 합리적인 적응 방법을 알아내는 지적 활동
ko.wikipedia.org
핵심을 보면 지능을 "새로운 대상이나 상황에 부딪혀 그 의미를 이해하고 합리적인 적응 방법을 알아내는 지적 활동의 능력"라고 정의할 수 있겠네요.
나무 위키에서는 아래와 같이 나와 있어서 정확히 정의할 수 없겠네요.
(위의 정의들을 보고 나니 인공지능이라는 말은 정말 정의하기 어려운 말인 것 같습니다. ^^)
나무 위키 말고 그냥 위키의 내용을 기반으로 한번 생각해보시지요. 사람이 새로운 대상이나 상황에 부딪혀 그 의미를 이해하기 위해서 어떻게 하나요? 직설적으로 말씀드리면 보고, 듣고, 느끼고 생각하는 것을 통해 그 의미를 이해할 수 있다고 하겠습니다. 즉, 감각기관을 통해 외부 현상을 받아들이고 과거의 경험, 지식 등을 통해 그 의미를 알 수 있게 되는 것이지요. 아주 간단한 예로는 고양이를 보고 (강아지가 아니라) 고양이인 것을 알고, 휴대폰 벨소리를 듣고 (초인종이 아니라) 전화가 온 것을 알 수 있는 것이지요. 따라서 지능이 있다는 것은 인지능력이 있는 것을 의미한다고 할 수 있겠습니다. '인지'라는 말은 간단히 말하면 고양이와 휴대폰 예에서 처럼 '안다'는 것입니다. (설명하다 보니 '안다'라는 게 참 애매한 의미인 것 같습니다. 말장난 같이 들린 수 있지만 안다는 것은 깊이와 넓이의 한계로 결국에는 정확히(?) 알 수 있는 것은 아무것도 없을 것 같다는 생각이 드네요.^^) 사람에게는 너무나 당연한 예를 들어서 오히려 이상할 수 있겠지만 컴퓨터가 이러한 일을 (사람 수준으로) 할 수 있게 된 것은 불과 10년도 안됩니다. 그럼 이러한 인지영역에는 어떤 것들이 있을까요? 시각을 통해 알아내는 시각인지, 언어를 통해 그 의미를 알 수 있는 언어인지, 소리를 통해 의미를 알 수 있는 사운드인지 등이 있을 것 같습니다. 촉감을 통한 인지도 있을 수 있겠네요.
학회를 통해 알아본 영역
인공지능 관련 주요 학회로는ICCV(International Conference of Computer Vision), CVPR(Conference on Computer Vision and Pattern Recognition), ECCV(European Conference on Computer Vision) 등 시각인지를 다루는 Multimedia(Computer vision) 관련 학회가 있습니다. 그리고 ACL(Association for Computational Linguistics (ACL)), NeurIPS(Neural Information Processing Systems), 등 언어인지를 주로 다루는 NLP(Natural Language Processing) 관련 학회가 있습니다. 기계학습과 관련해서는 ICML(International Conference on Machine Learning), ICMI(International Conference on Multimodal Interaction)등의 학회가 있습니다. 음성/신호 처리 관련해서는 ICASSP(International Conference on Acoustics, Speech, and Signal Processing)가 있습니다. 물론 인공지능과 조금 거리가 있는, 이전부터 있었던 WWW, KDD, SIGMOD 등 인터넷, 데이터 마이닝, 데이터베이스와 관련된 학회도 있습니다. 인공지능이 'AI'라는 단어에 대한 불신이 팽배했던, 그래서 연구에 지원을 못 받았던, 그래서 연구가 활발하지 못했던 시기인 'AI Winter' 시절을 마치고 인기를 끌게 된 시작점이 Computer Vision 분야이기 때문에 관련된 연구와 학회가 가장 먼저 많이 확산되었다고 할 수 있습니다. 이후 자연어 처리나 신호처리 등으로 관련 연구와 실험이 확대되어 많은 성과물은 만들게 되지요.
이제는 연구소에서만 인공지능을 만드는 것이 아닌 상황입니다. 잘 아시는 것처럼 연구뿐만 아니라 이미 실생활에서도 많이 쓰이는 제품/서비스들이 만들어지고 있습니다.(물론 말만 인공지능이라고 가져다 붙인 제품/서비스도 많지만요.) 특히, 오픈 소스 프로젝트의 발달에 따라서 많은 개발과 관리가 더욱 적은 비용과 노력으로 가능하게 되고 있습니다. (물론 발달은 끝이 없을 것 같습니다.) 이러한 움직임은 특히 소프트웨어 거대 기업의 주도로 더욱 활발하게 이루어지고 있습니다. Facebook(Meta), Amazon, Apple, Netflex, Google, Microsoft 등이 대표적인 기업입니다. 아, 하드웨어 기업이긴 하지만 엔비디아(Nvidia)의 역할도 언급을 안 할 수는 없겠군요. GPU(Graphics processing unit)라는 반도체 칩을 생산하는 회사로 이 칩의 대중화로 인해 딥러닝을 실제로 만들 수 있게 되었다고 할 수 있겠습니다. GPU가 없었다면 딥러닝 훈련에 몇 달, 몇 년이 소요됐을 텐데 GPU를 통해 많은 시간을 혁신적으로 단축할 수 있게 되었습니다.
인공지능의 혁신을 불러온 AlexNet과 ResNet을 포함한 간단한 인공지능의 역사에 대해서 이야기했고 주요 학회들을 통해 Computer Vision, NLP, 음성/신호 처리 등의 연구분야가 있다는 것을 알아보았습니다.
기계학습에 대한 분류는 아래 스탠포드 강의를 참고해주세요.
https://bigdatamaster.tistory.com/142
스탠포드 기계학습 강의 Lecture 1 - Stanford CS229: Machine Learning - Andrew Ng (Autumn 2018)
오래된(?) 강의지만 다시 봐도 참 좋은 강의입니다. 앤드류 응 교수님의 스탠포드 컴퓨터 사이언스 과목의 299번 과목의 첫 번째 강의입니다. 앤드류 응 교수는 MIT에서 석사, UC버클리에서 박사를
bigdatamaster.tistory.com
'인공지능-기계학습' 카테고리의 다른 글
| DeepSeek 충격의 배경과 현상 및 원인 이해해기 (4) | 2025.02.01 |
|---|---|
| 스탠포드 기계학습 강의 Lecture 1 - Stanford CS229: Machine Learning - Andrew Ng (Autumn 20 (0) | 2022.02.27 |
| Machine Learning Engineer Interview Questions: Machine Learning-Related Questions (0) | 2021.11.06 |
| 인공지능 기계학습 용어 상식 - 지도학습/비지도학습/강화학습 (0) | 2021.07.04 |
| [연재] 고객분석 2 - 워드 클라우드를 이용한 고객 성향 분석 및 판단 (0) | 2021.06.12 |