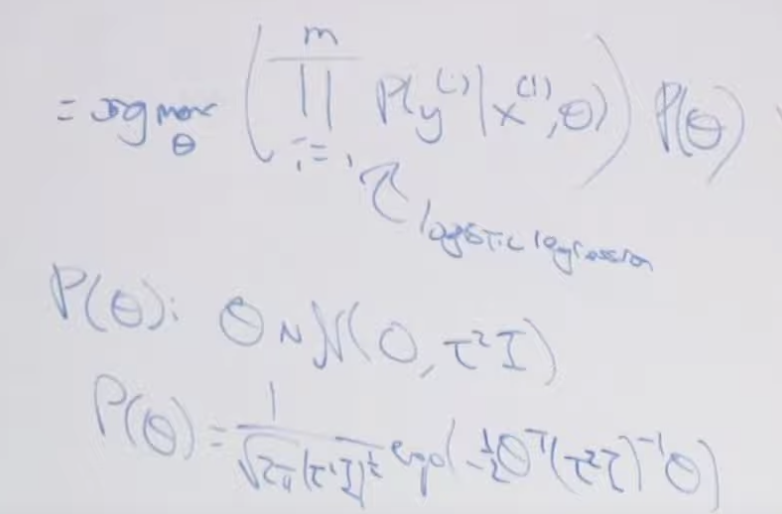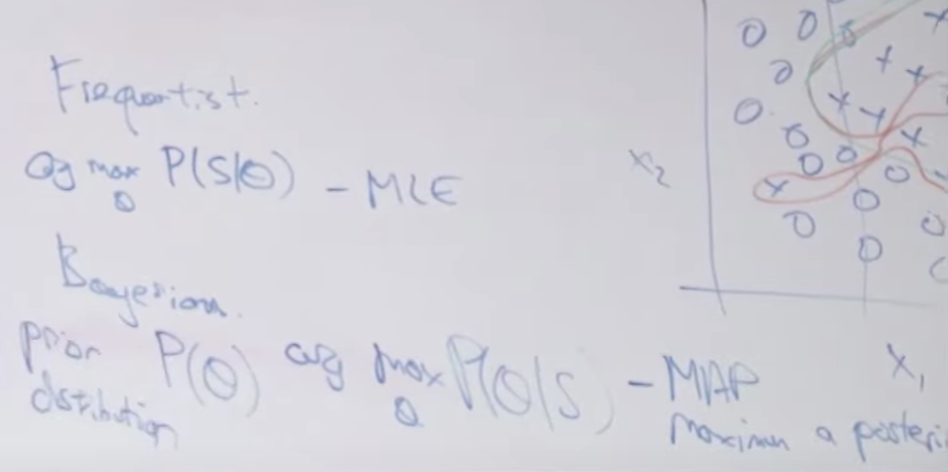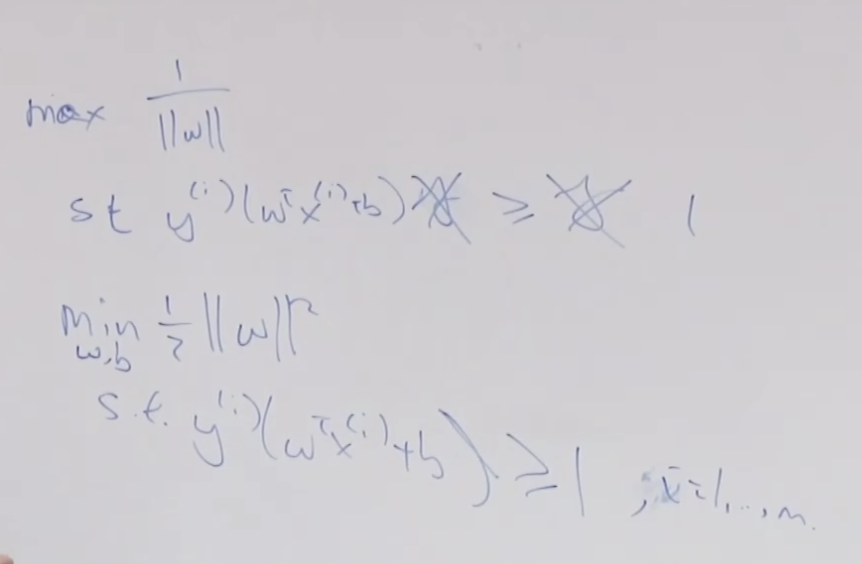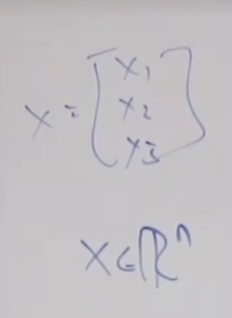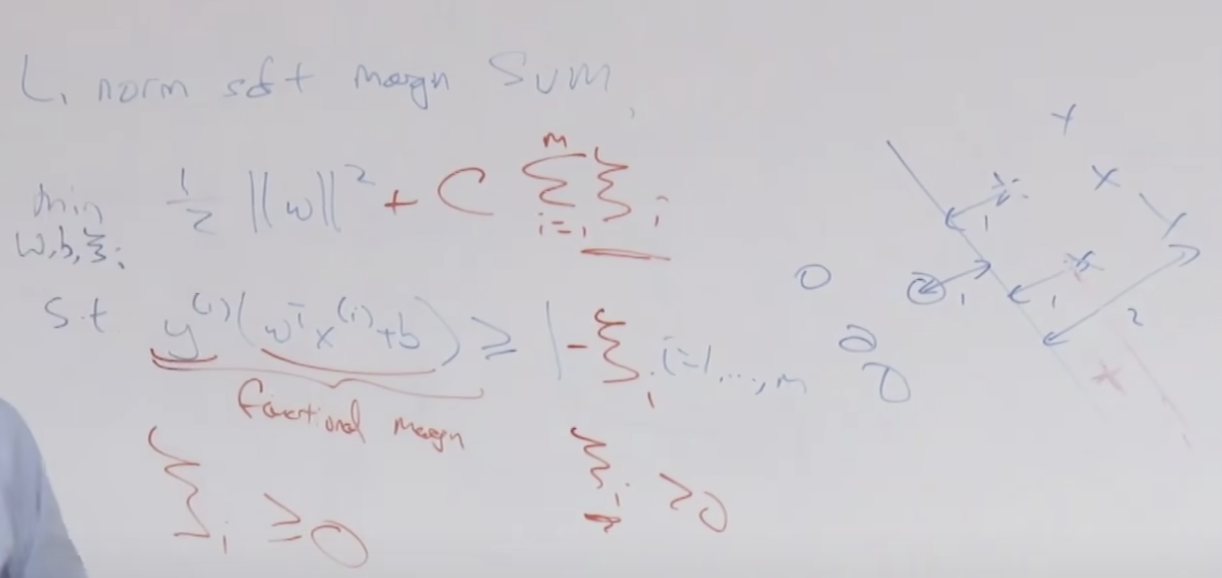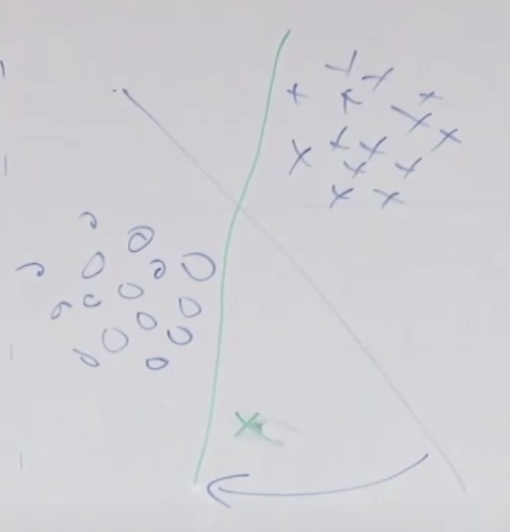Lecture 14 - Expectation-Maximization Algorithms | Stanford CS229: Machine Learning (Autumn 2018)
주요내용
- Unsupervised Learning(비지도 학습)
- K-means Clustering
- Mixture of Gaussian: Gaussian Mixture Model (GMM)
- EM (Expectation-Maximization)
- Derivation of EM
비지도 학습은 이전까지 배웠던 지도학습과 다른 학습 방법입니다. 예를 들면 지도학습은 긍정 데이터와 부정 데이터들이 주어지고 이들을 잘 분류하는 선형 회귀 모델 같은 것을 만들어서 잘 분류하는 회귀선을 만드는 것이었습니다. 그러나 비지도 학습은 레이블이 없는 데이터들이 주어지고, 지도학습에서는 (x, y)가 주어졌지만 비지도 학습에서는 x 만 제공됩니다. 이런 데이터 셋은 {x(1), x(2), ....x(m)} 으로 주어진 x 데이터 m개를 표현할 수 있습니다.
K-means Clustering
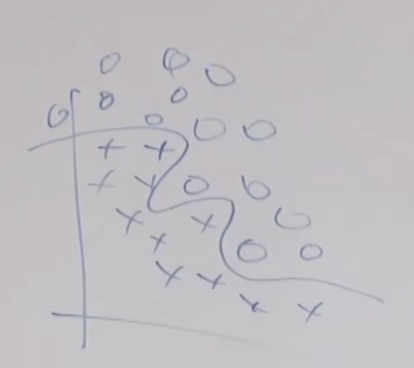
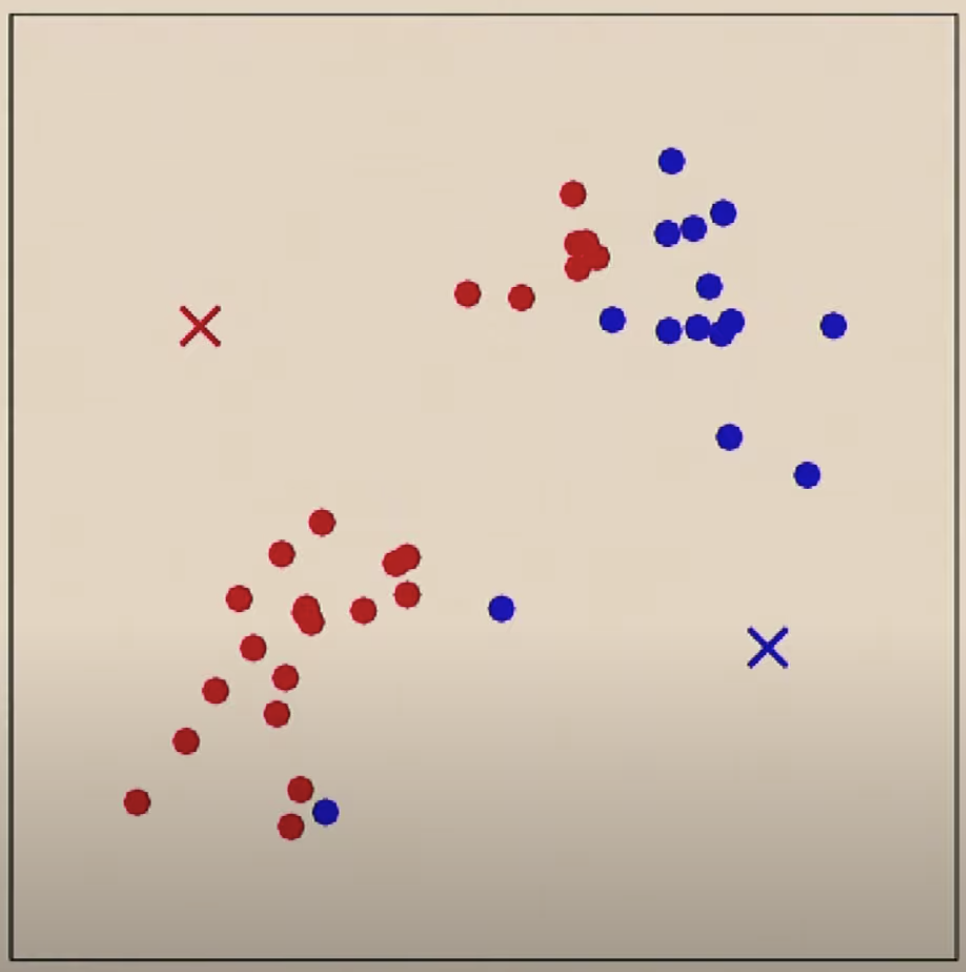
첫번째로 이야기할 비지도 학습은 클러스터링 입니다. x 데이터가 주어지면 두개 또는 그 이상의 그룹으로 묶는 알고리즘 입니다. 가장 많이 사용되는 클러스터링은 시장 구분(Market Segmentation)입니다. 예를 들면 사용자들을 클러스터링하여 어떤 다른 시장으로 그룹핑할 수 있는지 알 수 있습니다. 고객의 나이, 성별, 교육, 지역 등을 가지고 클러스터링 하여 다른 그룹으로 만들 수 있습니다.

위와 같은 데이터 셋이 제공되면 2개의 그룹으로 클러스터링 하기를 원할 것입니다. k-means의 경우 임의로 클러스터 갯수에 해당하는 위치를 선정하고

데이터 별로 두개의 중심점 중에서 어느 중심점에 더 가까운지를 기준으로 클러스터(색)를 정합니다.
두 번째로는 파란색 점들의 평균을 구해서 새로운 중심점으로 정합니다.

그리고는 새로 정해진 중심점을 기준으로 모든 점들에 대해서 다시 어느 중심점이 더 가까운지 비교하여 새로운 클러스터를 할당합니다.

그리고 다시 새롭게 할당된 클러스터의 중심점을 구합니다.

이런 클러스터를 할당하고 새로운 중심점을 구하는 동작을 반복하다 보면 특정 지역에 중심점이 수렴하게 됩니다.
이런 알고리즘을 k-means 알고리즘이라고 합니다.
레이블 되지 않은 Data x 가 주어졌을 때 알고리즘은 아래와 같습니다. 1. 먼저 중심점을 초기화 합니다. k 갯수 만큼의 중심점의 초기 값을 정하는 것인데 보통 random 값으로 잡지 않고 실제 Data x 값들 중에서 k 개를 임으로 선택합니다.

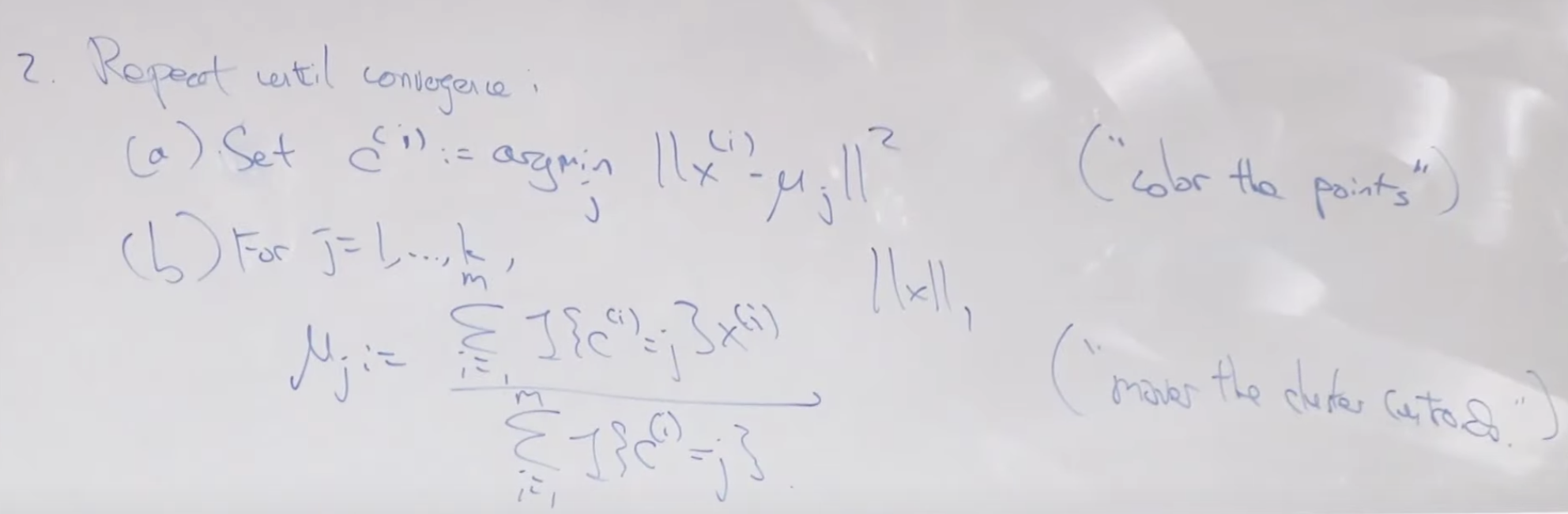
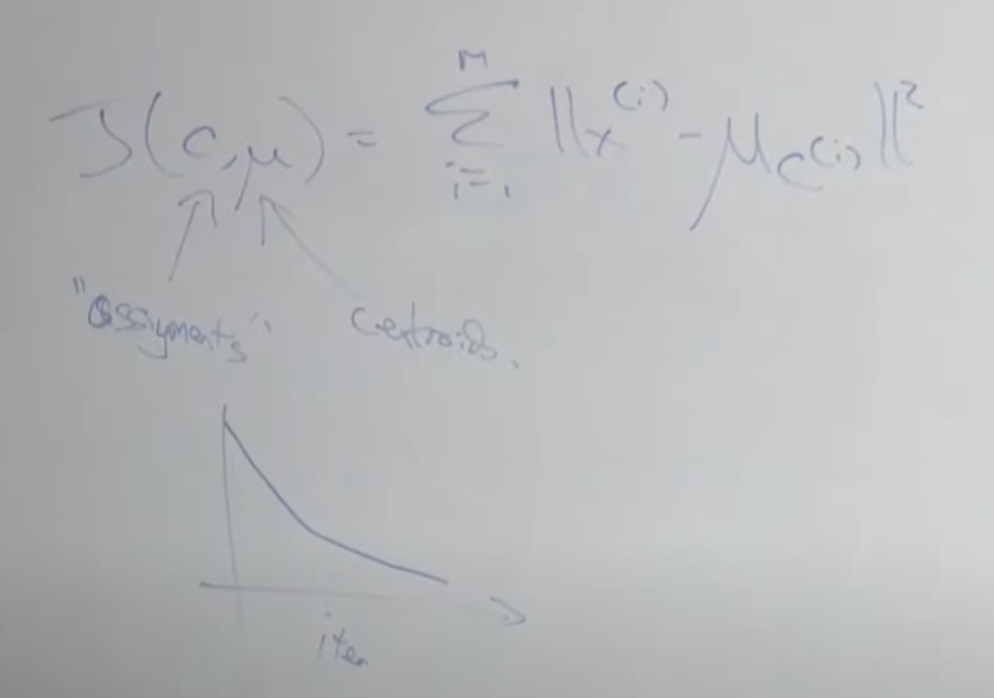
비용함수를 공식으로 적어보면 아래와 같습니다. c는 각 점들을 의미하고, u 뮤는 중심점을 의미 합니다. 각 x 값과 중심점과의 차이를 모두 더한 값으로 반복할 수록 작은 값으로 수렴하게 됩니다. 아주 많은 데이터를 가지고 이 알고리즘을 돌리다보면 아래의 그래프 처럼 수렴하기 전에라도 어느 정도 중심점이 변하지 않으면 종료하기도 합니다.
k-means 클러스터링과 관련해서 가장 많이 받는 질문은 어떻게 k 값을 정하는가? 입니다. 메트릭이 있기는 하지만 잘 쓰지는 않습니다. 보는 사람마다 다르게 판단할 수 있기 때문에 모호합니다.

오히려 목적에 맞게 k를 정하는 것을 권합니다. 예를 들어 마케팅을 위해 마켓 세그멘테이션이 필요하고 이를 위해 클러스터링을 한다고 했을때, 그룹핑을 4개로 할 수도 있고 100개로 도 할 수 있지만 업무적으로 프로모션을 위한 그룹 설계가 4개로 준비되어 있을 경우 4개로 그룹핑하여 제공해야 실무에서 마케팅에 사용할 수 있습니다.
k-means 알고리즘은 로컬 미니멈에 빠질 수 있습니다. 이 말은 초기 중심점 값을 어떻게 정하냐에 따라서 알고리즘을 실행할 때마다 다르게 그룹핑 될 수 있다는 의미입니다. 이런 로컬 미니멈에 빠지는 것을 방지하는 방법중 하나는 여러번 알고리즘을 실행 시키고 나서 비용함수의 값이 제일 작은 결과로 정해진 클러스터 결정을 선택하는 것입니다.
Density estimation
비행기 엔진을 만드는 공장에서 만들어진 엔진의 불량을 탐지하는 모델을 만든다고 생각해 보시죠. 시험 테스트 중에 나온 데이터인 진동 Vibration과 발열 Heat을 가지고 그래프를 만들었을 때 아래와 같이 그려진다고 하겠습니다. 이 때 녹색 점과 같은 데이터를 만들어낸 비행기 엔진의 경우 이상 탐지(Anomaly Detection)으로 탐지 할 수 있습니다.

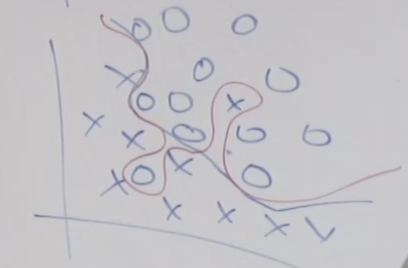
그러나 아래와 같이 분포가 간단하지 않은 경우 그룹핑을 하기 매우 어렵습니다. 이럴때 아래쪽에 있는 두개의 타원형 형태의 가우시안 분포와 이 타원형의 왼쪽에 연결된 또 다른 두개의 타원형 형태의 가우시안 분포, 즉 2개의 가우시안 분포로 전체 분포를 설명할 수 있습니다.

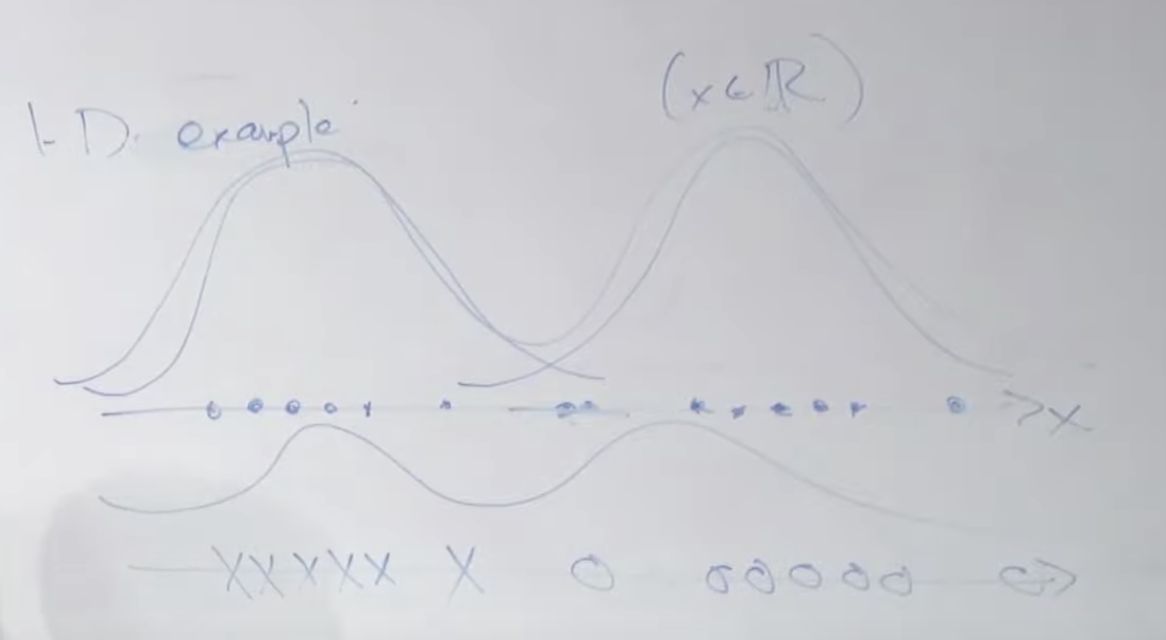
1차원 가우시안 분포를 예를 들어 보겠습니다. 아래와 같이 X 데이터가 주어졌을 때 이것은 2개의 가우시안 분포에서 왔을 수 있습니다. 그리고 이번 예시의 경우 두 개의 분포를 연결하면 중앙 부분은 확률이 낮아지는 부분으로 구성된 하나의 분포 곡선을 그릴 수 있습니다. (아래쪽 쌍봉 곡선)
Mixture of Gaussians Model: Gaussian Mixture Model (GMM)
이러한 방법으로 여러개의 다변량 분포가 혼합되어 있는 경우 어느 분포에서 추출될 가능성이 높은지를 알 수 있습니다.
latent 는 hidden 또는 unobserved의 의미 입니다. z는 랜덤 변수값이고 다중 분포일때 z ㅌ {1, ... k} , x(i), z(i)는 결합 분포를 가지고 있습니다. 이 것은 P(x(i), z(i)) = P(x(i) | z(i)) P(z(i)) 로 계산됩니다.
일반적으로 GDA Gaussian Distribution Analysis 는 2개의 분포, 즉 베르누이 분포를 말하지만 여기에서는 k개의 분포를 가지는 다형성의 파이를 갖습니다. 이 것이 첫번째로 GDA와 다른 것이고 두번째는 j분포 갯수의 차이 입니다. z(i)가 j번째 가우시안 분포에서 나왔을때 x(i)가 나올 확률은 평균이 uj 이고 분산이 시그마j 인 정규분포에서 나올 확률과 같습니다. GDA와 가장 큰 차이점은 GDA는 데이터 y(i)가 관측된 값으로 주어진다는 것입니다.

만약 우리가 z(i)의 값들을 알고 있다면 MLE를 사용할 수 있습니다. 그때 가능도는 아래와 같이 구할 수 있습니다.

EM (Expectation-Maximization)
EM은 관측되지 않는 잠재변수에 의존하는 확률 모델에서 최대가능도(maximum likelihood)나 최대사후확률(maximum a posteriori, 약자 MAP)을 갖는 모수의 추정값을 찾는 반복적인 알고리즘을 말합니다. (위키피디아)
첫번째 E-step은 아래와 같습니다. 우리는 실제 z(i) 값을 모르기 때문에 주어진 값들을 이용해서 기대값을 찾는 단계입니다. 여기서 z(i)란 x(i)가 뽑힐 수 있는 특정 정규분포 j를 말합니다.

두번째 단계는 M-step 입니다. 앞에서 찾은 기대값을 최대로하는 모수 값을 찾습니다.
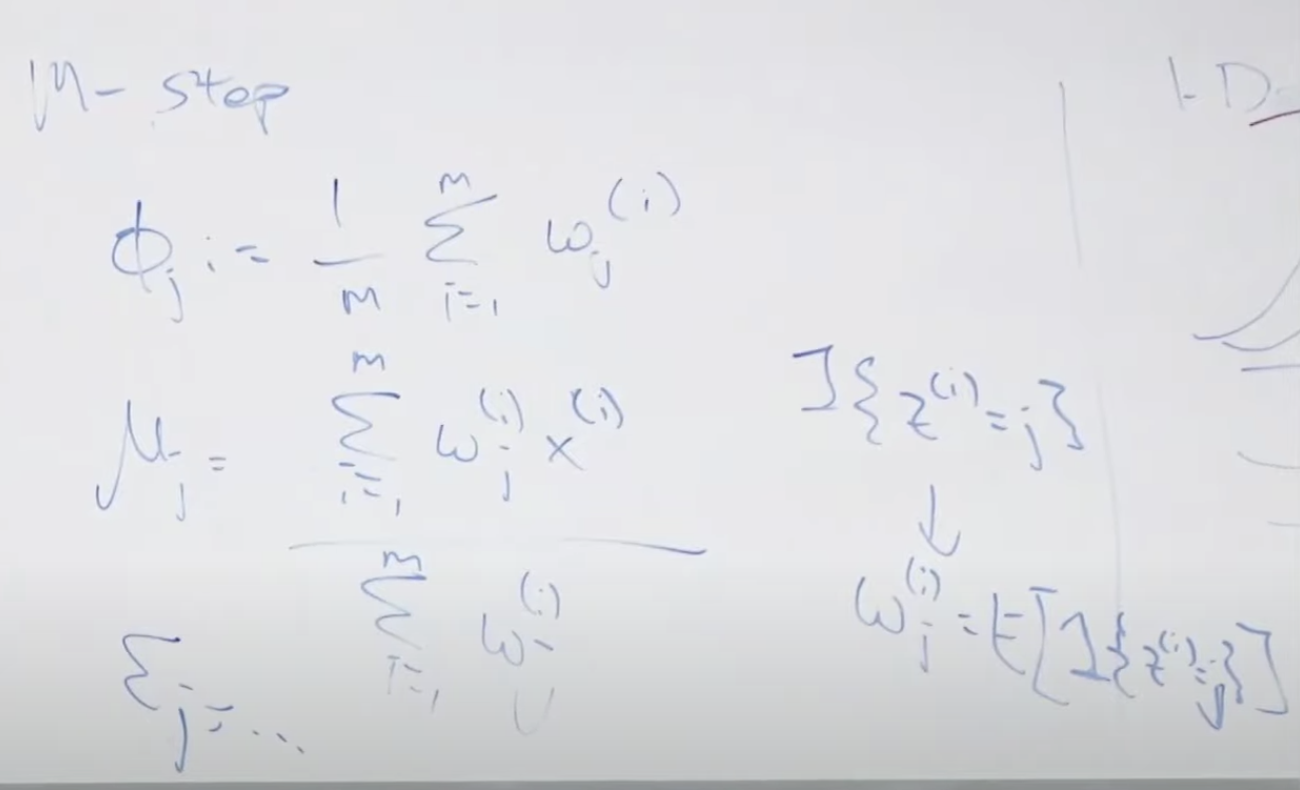

이러한 단계를 거처 기대값을 최대로 하는, 여러개의 분포가 합쳐지는 하나의 분포 곡선을 만들 수 있습니다. 이러한 곡선은 아래처럼 다양합니다. 이로써 찾은 함수를 통해 입력값 x를 실행했을때 결과 확률값이 특정 기준(입실론) 보다 크거나 같으면 정상적인 데이터이고 확률값이 작으면 이상탐지(Anomaly)로 판단할 수 있습니다.

Derivation of EM
이후 아래는 EM의 공식을 유도하는 내용입니다.
Jensen's inequality
함수 f를 아래로 볼록한 함수(Convex function)이라고 하고 x를 임의의 값이라고 할때, 공식 f(EX) <= E[f(x)] 를 만족합니다.



우리는 젠슨의 불균형 공식을 위로 볼록한 Concave 함수로 사용합니다. Concave 함수는 Convex 함수와 위/아래가 바뀐 함수이지요. 그럴 경우 위에서 설명한 모든 부등식을 반대로 바꾸면 됩니다.
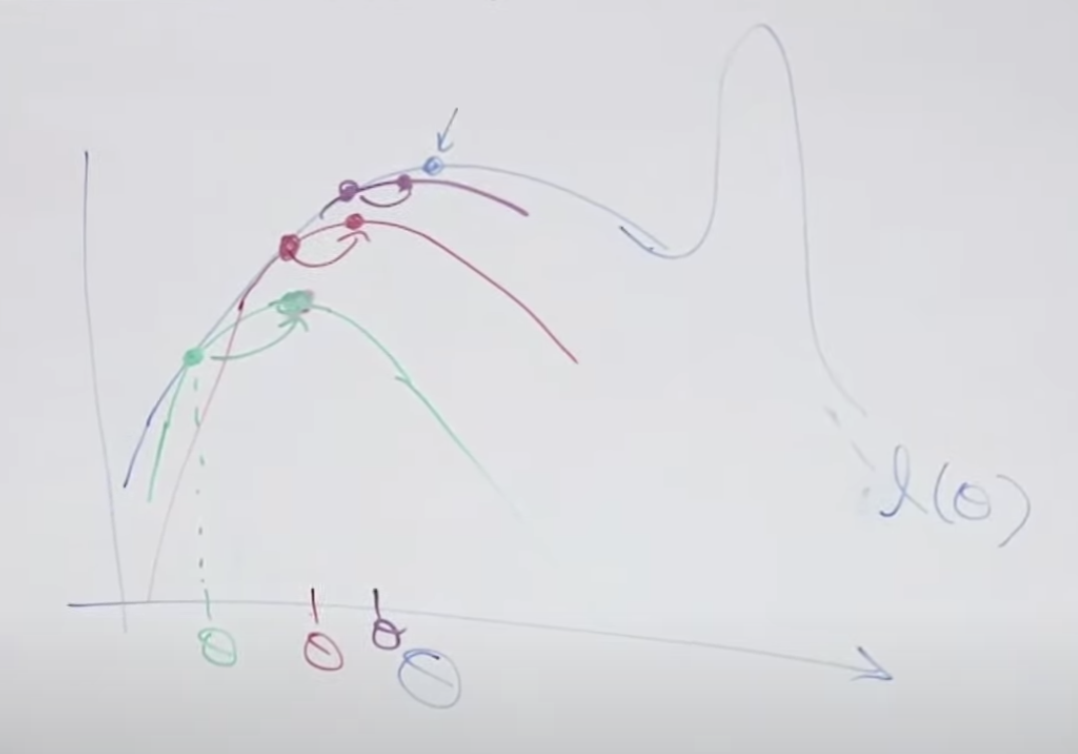
임의의 녹색 theta세타 값을 먼저 설정합니다. 이 값에 해당하는 함수곡선(녹색)을 만들고 이 함수와 목표 함수(검정색)가 만나는 점을 찾고 이 녹색 함수의 꼭지점을 찾습니다. 그리고 이 꼭지점으로 이동합니다. 이 꼭지점에 해당하는 theta값으로 변경 후 다시 함수를 찾습니다. 이러한 내용을 반복하면 검정색의 목표 함수의 지역 최대값(꼭지점)에 점점 가깝게 됩니다. 그러나 아래 그림의 오른쪽 처럼 목표함수가 여러개의 지역 최대값을 가지고 있는 경우 전체 최대값을 찾지 못할 수도 있습니다.
아래는 이러한 E, M 단계를 공식으로 풀이 증명하는 내용입니다.


위 공식의 변형에 필요한 기본 전제 공식은 아래와 같습니다.
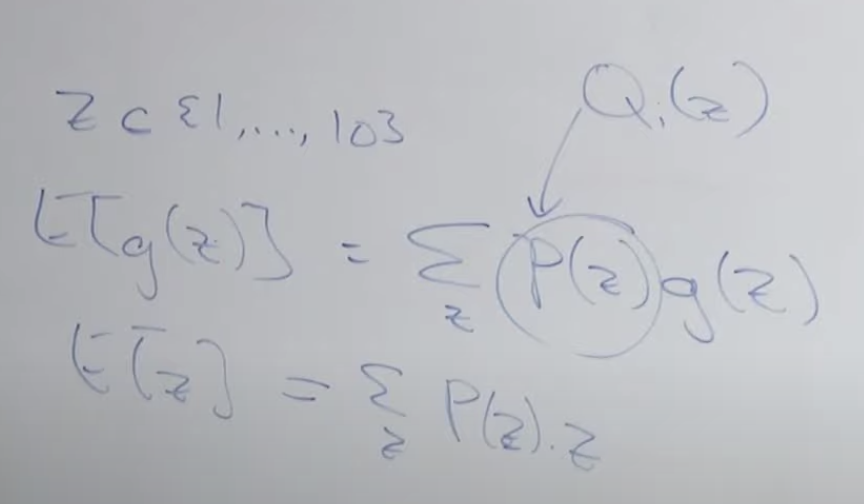


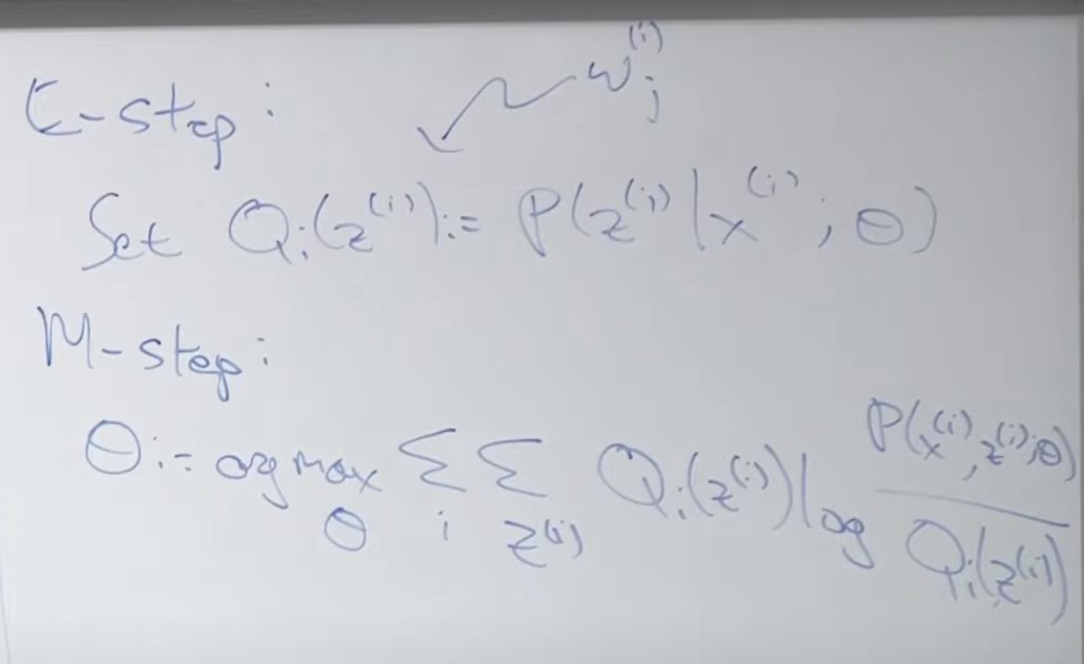
아래는 강의 동영상 링크 입니다.
https://www.youtube.com/watch?v=rVfZHWTwXSA&list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU&index=14