프로그램을 짜다보면 데이터를 정렬해야하는 경우가 자주 있다. 간단한 데이터 구조에서는 쉽게 해결되지만 복잡한 구조일때는 어려움을 느낀다. 이럴때 파이썬이 제공하는 정렬관련 내용을 잘 알고 있으면 많은 개발 시간을 절약할 수 있다. 간단한 것 부터 살펴 보자
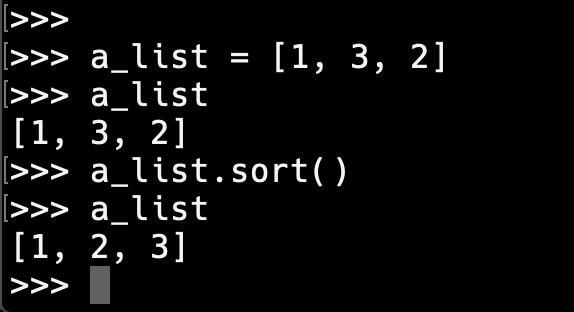
단순 리스트를 정렬하는 방법:
list의 sort() 메소드를 이용하면 된다. 실제 해당 리스트의 순서가 변경된다.
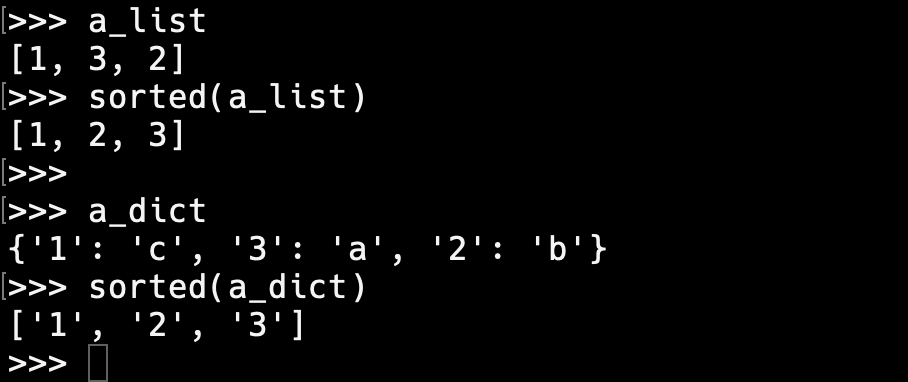
dect 사전을 정렬하는 방법:
sorted 함수를 이용한다. sorted는 파이썬 내장함수이다. 따라서, 별도 패키지 설치 없이 바로 이용할 수 있다. 사실 sorted 함수는 모든 형태의 정렬에 사용 할 수 있는 함수이다. (상기의 sort() 메소드는 리스트 객체에서만 이용가능하다) sorted()를 좀더 자세히 말하면 반복 가능한 객체를 입력 받아서 key 값에 따라 정렬하고 정렬된 리스트를 반환하는 함수이다. 아래와 같이 단순 리스트는 (value)값으로 정렬되고 사전은 key 값이 정렬된다.
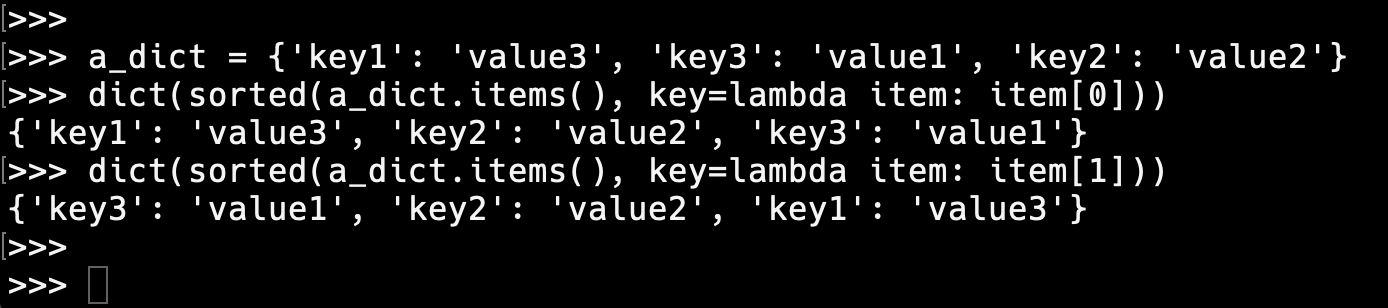
그런데 사전의 정렬 결과를 보면 키만 정렬되어 반환한다. 원하는 것이 사전 그대로의 내용이 키 순서대로 정렬되기를 바라는 경우가 많이 있다. 이러한 경우에 lambda 함수를 이용해서 해결 할 수 있다. (lambda함수란 메모리 절약을 위해 임시성으로만든 함수로 이름 없는 함수로 생성-사용-소멸이 자동으로 이루어지는 함수이다. 어찌보면 간단하게 동작하는 함수로써 당연하고 불편한 부분은 제외한 함수이다. 자세한 내용은 다른 포스트에서...) 여기서 item은 반복가능한 객체 중 하나를 의미한다. 따라서 첫번째 객체로 (key1': 'value3') 이 된다. 아래 예시와 같이 item의 인덱스를 0으로하면 key를 기준으로 정렬되고 1로하면 value를 기준으로 정렬된다. 입력데이터와 동일한 사전 형식을 유지하기 위해 반환되는 값을 dict()를 이용하여 사전으로 변경해 준다.
<코드 출처: https://docs.python.org/3/howto/sorting.html> 그러나 이러한 방법의 단점은 데이터 구조의 변환 시 매우 주의해서 코드를 작성해야한다. 왜냐하면 6라인의 끝부분에 student[2] 처럼 상수(2)가 코드에 포함됨으로써 나이 앞에 새로운 항목 하나가 추가될 경우 동일한 작동을 위해서는 (3으로) 변경해 주어야 한다.
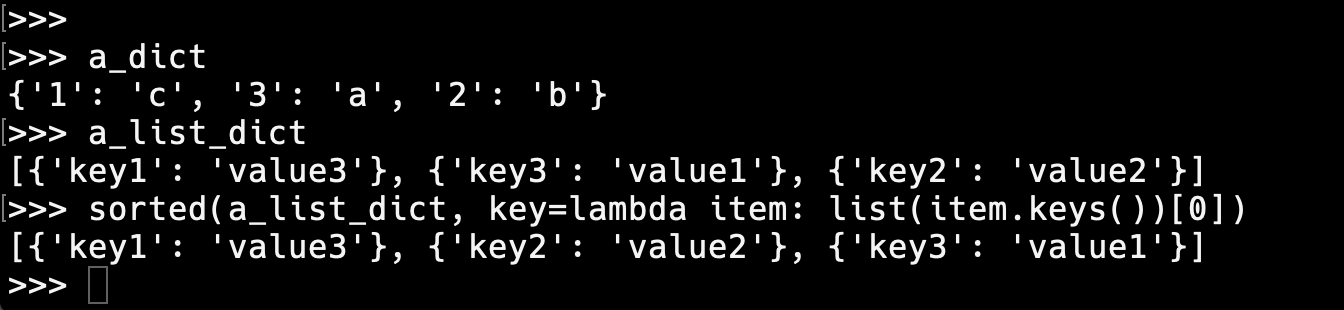
리스트 안에 들어있는 사전을 정렬하는 방법
json 포맷을 사용할 경우 리스트 안에 사전이 들어있는 형태의 데이터 구조가 된다. 이런 형태의 정렬은 바로 위의 내용을 살짝 바꾸어서 사용가능하다. lambda 함수에서 받게되는 하나의 객체가 사전인 경우 이므로 keys() 메소드를 이용하면 된다. 아래 예시에서는 항목의 key가 하나이므로 .keys() 메소드를 통해 반환되는 값을 리스트로 바꾸고 첫번째[0]를 선택하면 모든 객체의 키값이 반환되게되고 이를 기준으로 정렬하게 된다.
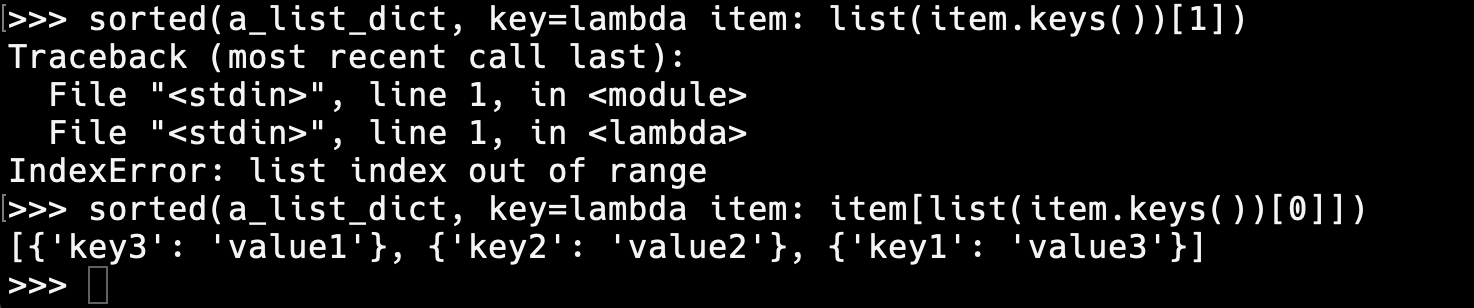
그렇다면 value를 기준으로 정렬하려면 어떻게 해야할까??? 앞선 예제에서 처럼 0을 1로 바꾸면 되지 않을까? 라고 생각할 수 있지만 의미가 다르기 때문에 에러가 난다. 여기서의 0은 keys()로 반환받은 키값들 중에 첫번째([0])라는 의미 이기 때문에, 1로 바꿀 경우 두번째 키값이라는 의미가되고 이것을 찾으려하지만 첫번째 항목 데이터({'key1': 'value3'})에서 보다시피 key 값은 하나('key1')밖에 없기 때문에 에러가 발생한다. 따라서 key가 아니라 value를 기준으로 정렬하기 위해서 value를 나타내는 형식을 작성해야한다. 다소 복잡하지만 그 내용은 item[list(item.keys())[0]] 이다.
복잡한 구조에 대한 정렬이 필요한 경우 2
위의 '복잡한 구조에 대한 정렬이 필요한 경우' 에서 처럼 하면 위에서도 말했지만 단점이 있다. 데이터 구조에 따라 코딩 내용을 바꿔줘야 할 경우가 있다. 치명적일 수 있다. 그래서 아래의 내용 처럼 클래스로 만들어서 관리하면 데이터 구조의 추가 삭제에 따른 순서 걱정 없이 정렬을 할 수 있다.