이번 강의 주요내용
Generative Learning Algorithm
- Gaussian Distributed Analysis(GDA)
- Generative vs Descriptive comparison
- Naive Bayes(나이브 베이즈)
Generative learning algorithm
지난 시간에 배운 로지스틱 회귀에 대해서 다시 생각해봅시다. 종양을 보고 양성인지 음성인지 판단하는 모델을 생각해봅시다. 아래와 같이 x는 양성(암) o는 음성이라고 할 경우 우리는 선을 그려가면서 어떤 선이 가장 잘 판단하는지를 구분하는, 좋은 '선'을 찾는 문재로 생각할 수 있습니다. 이런게 Descritive 방법이지요.

로지스틱 회귀와 다르게 GLA는 알고리즘은 클래스의 특징을 먼저 배웁니다. 악성종양의 데이터들을 보면서 아! 악성종양은 위쪽에 모여있구나 이것을 배우고 음성종양의 데이터를 보면서 음성종양은 아래쪽에 모여있구나를 학습하게 됩니다. 그렇게 해서 악성종양 모델은 위쪽 빨간색 동그라미에 모여있고 음성 종양모델은 아래쪽 빨간색 동그라미에 모여있다는 것을 모델이 학습하게됩니다. 이를 이용해서 새로운 빨간점 데이터가 들어왔을때 어느 모델의 동그라미에 속하는 지를 보고 판단하는 방법이 GLA(Generative learning algorithm)입니다.

다시 말하면 Descriptive 학습은 x가 주어지면 h(x)함수가 0인지 1인지 알려주는 모델이었습니다. 그에 반해 Generative 는 먼저, y(양성 또는 음성 중 하나의 클래스)가 주어졌을때 x가 나올 확률을 계산합니다. 전체 중에 y의 확률은 전체 데이터를 가지고 구할 수 있습니다(사전확률). 여기에 베이즈 룰을 적용해서 x가 주어졌을때 y가 1(악성)일 확률을 구할 수 있습니다. 이러한 방법이 Generative 알고리즘의 프레임웍 입니다. 사전확률과 개별 사건의 확률을 구하고 이를 이용해서 새로운 x에 대한 y일 확률을 구할 수 있습니다. 이 설명을 관련 공식으로 정리하면 아래와 같습니다. 왼쪽이 사전확률과 개별확률을 구하는 공식이고 오른쪽이 새로운 x가 들어왔을 때 확류을 구하는 공식입니다. 잘 보시면 왼쪽에서 빨간색 사각형 부분들과 오른쪽 아래에 빨간색 사각형의 공식을 이용해서 오른쪽 위에있는 P(y=1 | x)를 구할 수 있습니다.
오늘 두가지 유형의 데이터(연속형 continuous-GDA, 이산형 discrete-Naive Bayer)에 대한 모델을 배울 것 입니다.
*** Discriminative와 Generative 모델의 이해를 위해 위키피디아에서 Generative model 에 대한 정의를 찾아봤습니다.
In statistical classification, two main approaches are called the generative approach and the discriminative approach. These compute classifiers by different approaches, differing in the degree of statistical modelling. Terminology is inconsistent,[a] but three major types can be distinguished, following Jebara (2004):
- A generative model is a statistical model of the joint probability distribution {\displaystyle P(X,Y)} on given observable variable X and target variable Y;[1]
- A discriminative model is a model of the conditional probability {\displaystyle P(Y\mid X=x)} of the target Y, given an observation x; and
- Classifiers computed without using a probability model are also referred to loosely as "discriminative".
Discriminative 모델은 조건부 확률이고 Generative모델은 결합 확률 분포를 이용한다는게 다른 점 입니다. 강의 중에도 내용이 나오니까 계속 보겠습니다.
Gaussian Distributed Analysis(GDA)
GDA의 가정들은 아래와 같습니다. 가장 중요한 가정은 사용되는 데이터가 가우시안 분포라고 가정합니다.
단일 피처 데이터에 대해서는 표준 정규 분포를 이용하면되고 여러 피처에 대해서는 다변량 정규 분포를 이용합니다. 하나의 피처 데이터 항목으로는 많은 문제를 해결할 수 없으므로 여러 피처를 이용하는 다변량 정규 분포를 배우는 것이 중요합니다.

아래는 2개의 피처를 사용하는 2차원 다변량 정규 분포를 시각화 한것 입니다. 이미지 위에 있는 공식의 ∑ 값에 따라 그래프의 모습이 바뀌는 것을 보실 수 있습니다.

이러한 그래프를 2차원 그래프로 바꾸면 아래와 같습니다.(가운데 각 동그라미는 모두 완벽한 원입니다.)
가중치를 바꾸자 완벽한 원이 었던 것이 타원형이 되었습니다.

y의 각 클래스 별로 확률을 구하는 공식은 아래와 같습니다. 둘다 정규분포를 가정하고 작성된 것입니다. 그래서 정규분포의 확률밀도함수와 유사합니다.

그리고 여기에 사용되는 파라메타에 대해서 이야기합니다. 뮤0, 뮤1, 입실론, 피/파이 입니다. 이러한 파라메타를 잘 훈련해서/찾아서 모델을 만들면 앞의 그림에 있는 베이지안 룰을 통해서 새로운 데이터 x가 주어졌을 때 y가 1일 확률을 구할 수 있습니다.

훈련데이터에 대한 표기 법을 설명합니다. 그리고 조인트(결합) 가능도를 구하는 공식을 유도합니다.
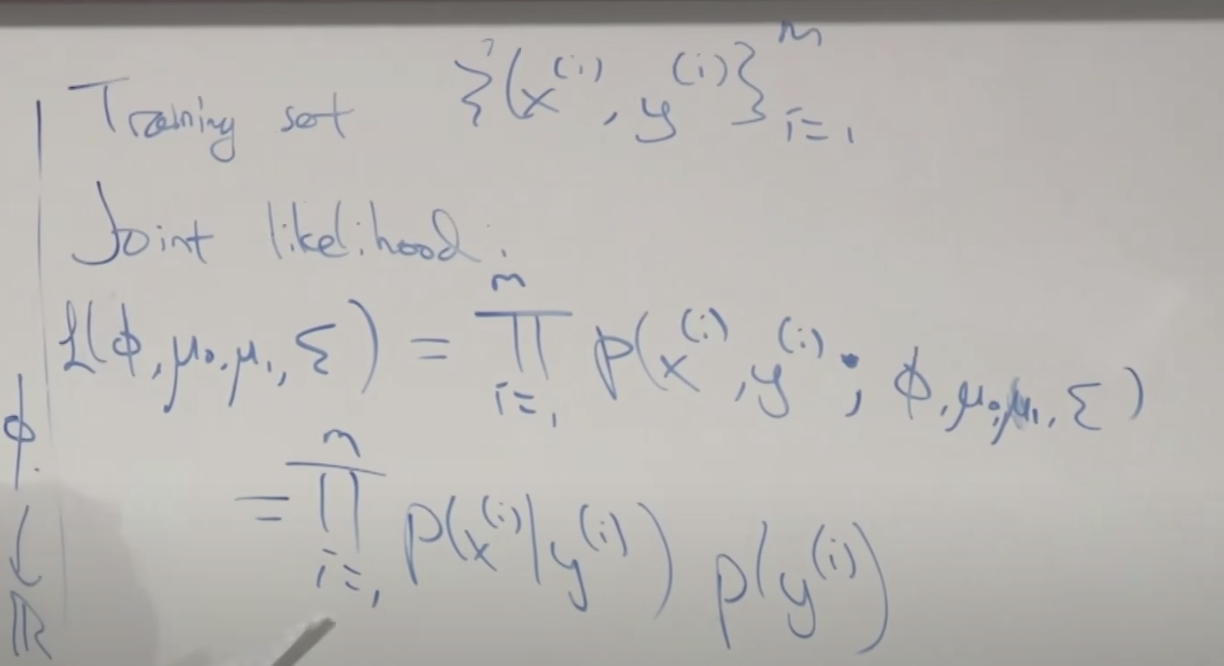
조건 가능도를 구하는 공식을 유도합니다.

최대 가능도 추정법(MLE)을 통해서 파라메타들을 찾습니다.

각 파라메타들을 공식으로 유도한 내용입니다. 직관적으로 설명하면 오른쪽 아래의 그림처럼 각 클래스 집단의 중간에 있는 값이 평균(뮤)가 됩니다. 뮤0는 전체 데이터중에 y가 0인(음성인) 데이터 피처 벡터들의 합을 y가 0인(음성인) 데이터의 전체 개수로 나눈 값입니다. 즉, 평균값 입니다. 그래서 집단의 중간에 위치하게 됩니다.

입실론도 아래와 같은 공식으로 유도됩니다. 예측 시에는 확률 값을 최대로하는 값을 찾는 argmax함수를 이용합니다.
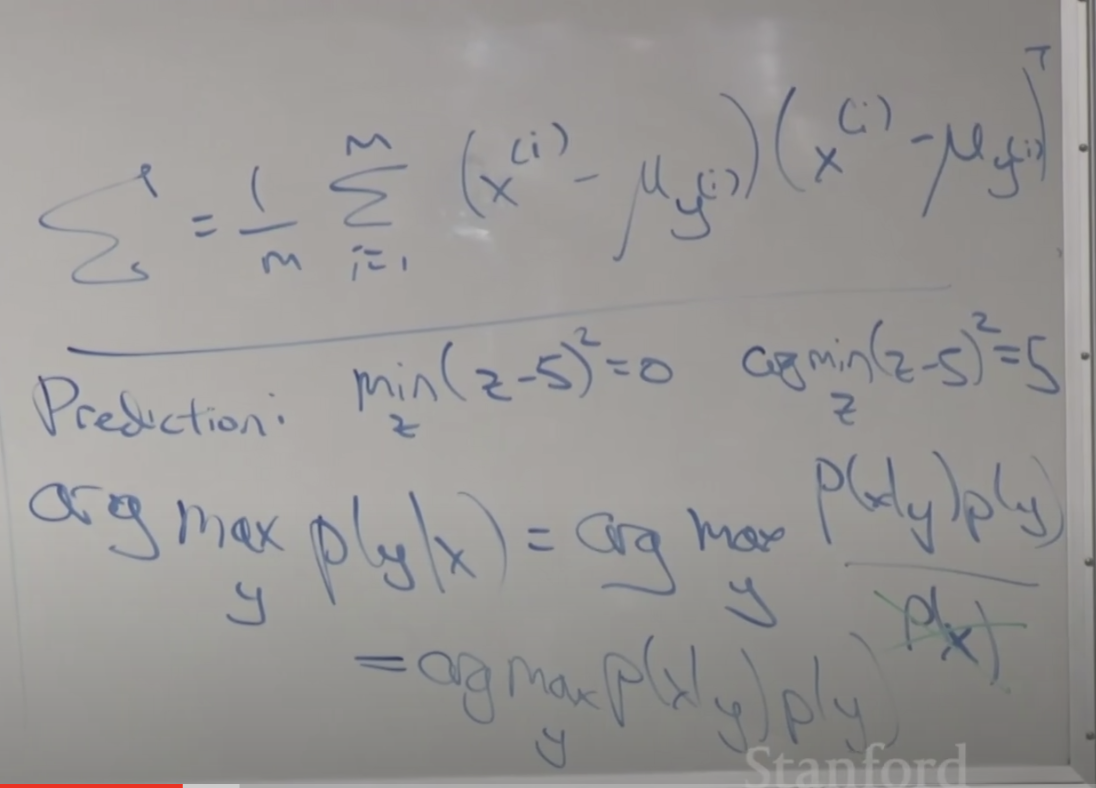
Generative vs Descriptive comparison(37:00)
선형회귀모델의 최초 학습을 위해 변수를 0으로 셋팅하고 선을 그어본 그림입니다. 반복 iteration을 할 수록 잘 구분하는 선으로 바뀌는 것을 보여 줍니다.
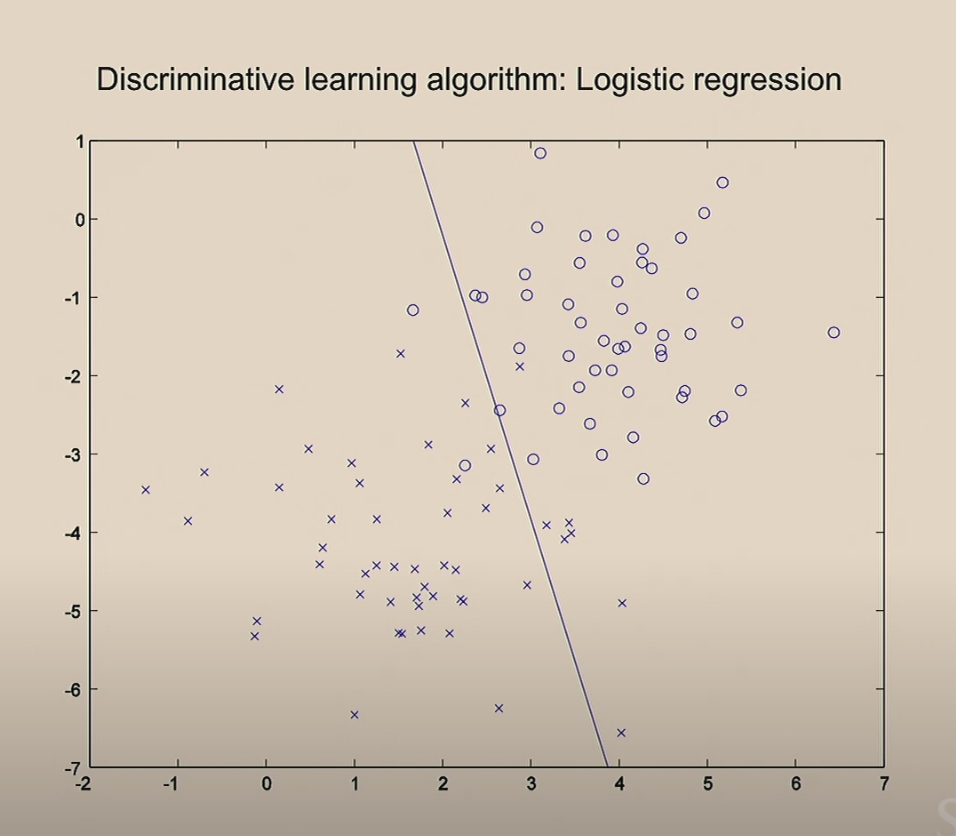
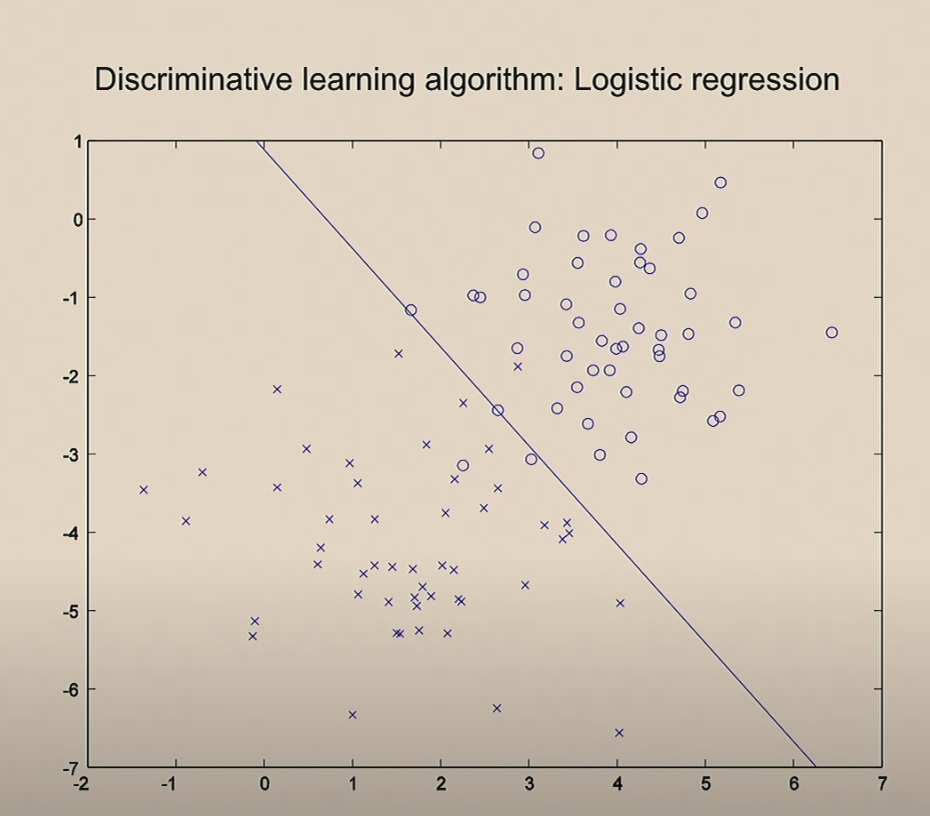
이것이 로지스틱 회귀를 이용한 분류 학습 알고리즘 입니다.
반면 GDA는 각 클래스의 분포를 먼저 계산하고 각 분포간의 거리를 기준으로 분류 선을 그립니다. 동그라미 데이터들을 보면서 동그라미 클러스터(집단)의 중앙 위치를 찾습니다. 그다음 x 데이터들을 보면서 x 클러스터의 중앙 위치를 찾습니다. 둘사이의 거리 중간을 기준으로 선을 긋습니다.
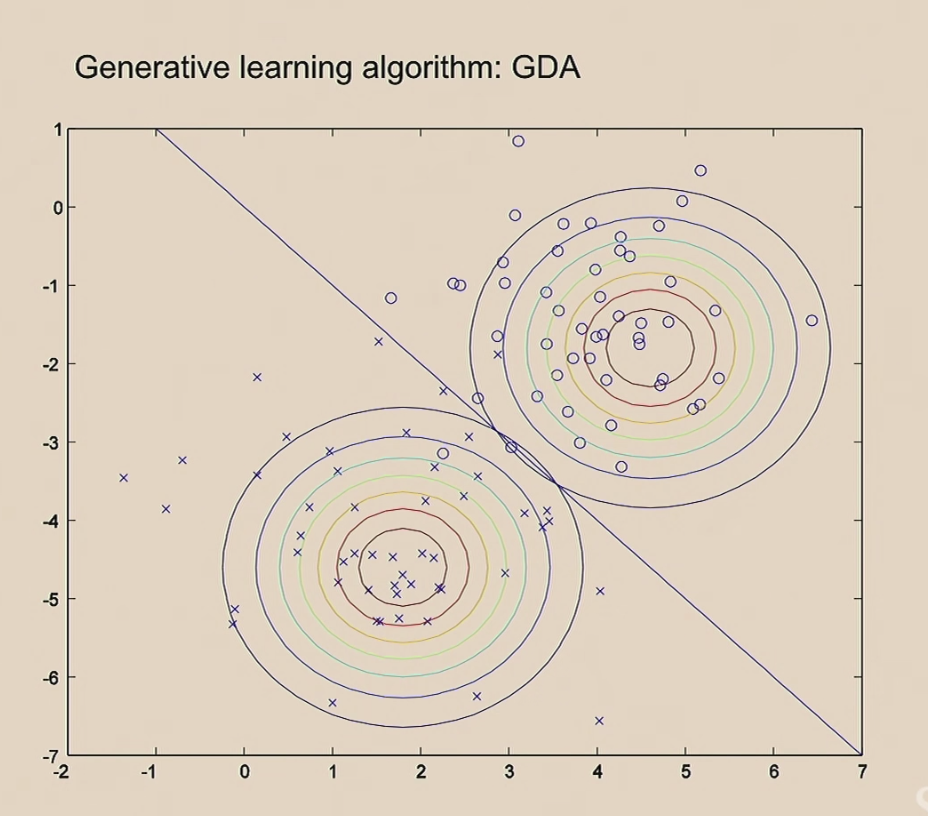
두 모델의 결과를 비교해보면 아래와 같습니다.
결국 둘다 모두 분류 모델을 만드는 것인데 그 방법이 서로 다르네요 즉, 직선을 그어가면서 제일 잘 분류하는 선을 찾을 것인지 아니면 분류된 분포를 보고 두 분포를 분리하는 선을 찾을 것인지가 다릅니다.
훈련 데이터가 하나인 경우를 가정하고 설명합니다. 종양의 크기라고 해보죠 x로 표시된 것은 악성종양, o로 표시된 것은 음성 종양입니다. 제일 위의 그래프는 직선에 종양 크기별로 표시한 내용이고 그 아래 두번째 그래프는 각 클래스에 대한 빈도를 그린 곡선입니다. 두 개의 정규분포 그래프가 보이네요. 그리고 제일 아래 그림은 새로운 예측 데이터 x가 주어졌을 때 y가 1(악성종양)일 확률을 x의 크기에 따라 그려본 그래프 입니다. 정확하게 시그모이드 함수와 일치합니다.
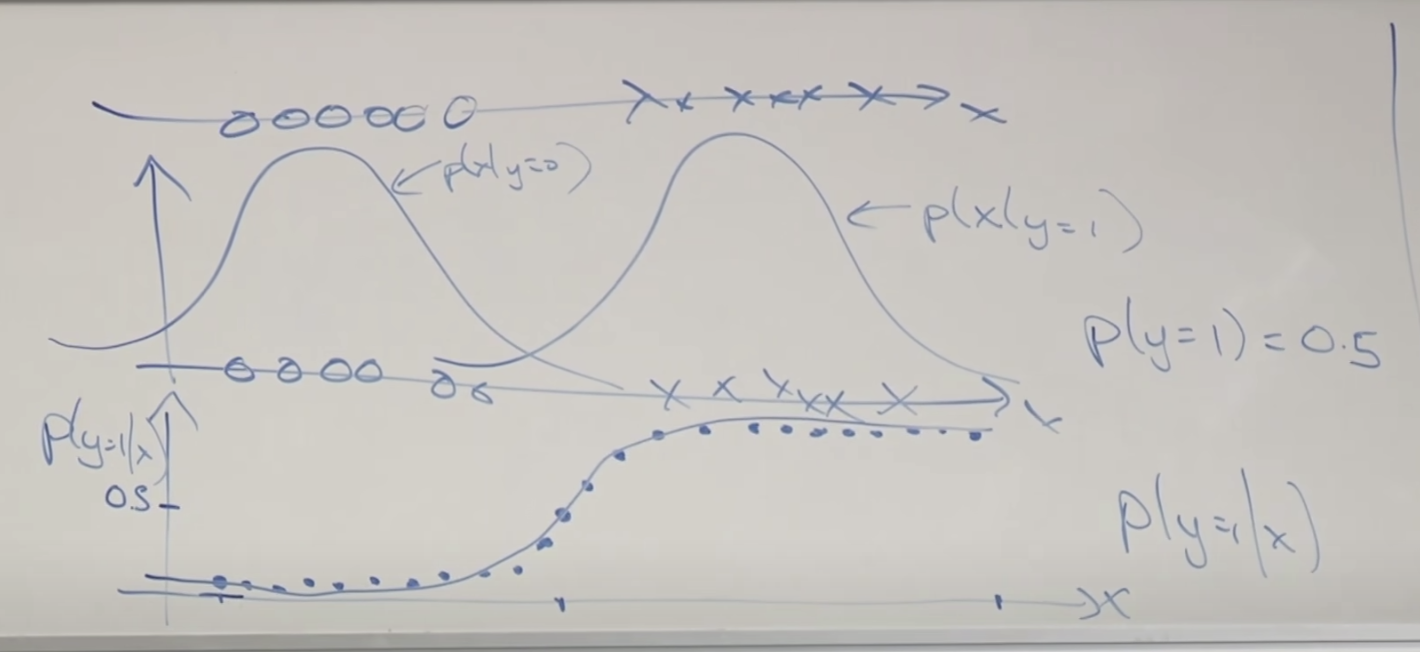
결국 두 모델 다 시그모이드 함수를 사용한 것과 같습니다. 그러나 접근 방법이 다르기 때문에 위에서 보여드린 두 모델의 비교 그림에서 보이는 것처럼 서로 다른 직선을 만듭니다.
두 모델의 차이점과 특징, 언제 GDA가 더 유용한지?
- GDA는 정해진 분포를 가정하고 계산하기 때문에 훈련데이터의 분포를 잘 알고 있는 경우 사용하면 좋다.
- GDA가 더 가정에 강하기 때문에 더 잘 설명한다(중앙의 화살표처럼 GDA로는 로지스틱회귀를 설명할 수 있지만 반대로는 안된다.)
- GDA는 적은 계산으로 좋은 성능을 낼 수 있다. (반복 계산할 필요없고 평균, 편차에 대한 행렬계산만 하면 끝난다)
- 로지스틱 회귀는 훈련데이터의 분포를 모를 때도 사용할 수 있고 좋은 결과를 나타낸다.
- 세상 대부분이 정규분포이기 때문에 데이터가 많이 있으면 로지스틱 회귀를 사용하는게 좋다.
- 데이터를 점점 더 많이 사용할 수 있게되고 계산 비용(인프라 비용)이 저렴해짐에 따라 로지스틱 회귀를 사용하는 사례가 많아진다.
- 데이터가 적은 상태에서 모델을 만드려면 고급 스킬이 필요하다. 적은 데이터로도 효과적인 모델을 만들 수 있다.

Naive Bayes 나이브 베이즈
Generative 모델중 하나인 나이브 베이즈에 대한 설명 입니다.
이메일에 대한 스팸 여부를 분류하는 모델 개발을 생각해 봅시다. 10,000개의 단어가 있는 사전을 가지고 있다고 합시다. 하나의 이메일 x 에 대해서 해당 단어가 있는지(1) 없는지(0)에 따라서 아래 처럼 표시할 수 있습니다. (One-hot Encoding)
아래와 같은 가정을 합니다.
각 단어들은 독립적이라고 가정하고 각각의 확률은 체인 룰을 통해 아래와 같이 정리될 수 있습니다.
찾아야할 파라메타는 스팸메일(y=1) 일때 xj 단어가 나타날 확률과, 스팸메일이 아닐 때(y=1) xj 단어가 나타날 확률 입니다. 그리고 전체 메일중에 스팸메일이 나타날 확률 입니다.
GDA와 같이 조인트 가능도를 구합니다. 모습도 GDA와 유사하게 됩니다.

이번 강의 에서는 Generative 모델과 Discretive 모델의 차이와 Generative 모델에 해당하는 Gaussian Distributed Analysis 와 Naive Bayers 알고리즘에 대해서 배웠습니다.
아래는 강의 동영상 링크 입니다.
https://www.youtube.com/watch?v=nt63k3bfXS0&list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU&index=5












