가능도/우도/Likelihood
위키피디아
가능도
통계학에서, 가능도(可能度, 영어: likelihood) 또는 우도(尤度)는 확률 분포의 모수가, 어떤 확률변수의 표집값과 일관되는 정도를 나타내는 값이다. 구체적으로, 주어진 표집값에 대한 모수의 가능도는 이 모수를 따르는 분포가 주어진 관측값에 대하여 부여하는 확률이다. 가능도 함수는 확률 분포가 아니며, 합하여 1이 되지 않을 수 있다.
정의
확률변수 X 가 모수 θ 에 대한 확률분포 Pθ(X)를 가지며, X가 특정한 값 x로 표집되었을 경우, θ의 가능도 함수 L(θ |x) 는 다음과 같이 정의된다.
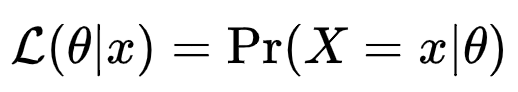
예 2
동전을 던져서, 앞면(H)이 나오는 확률을p_H 라고 하자. 이때, 앞면이 두번 나오는 확률은 p_H^2이다.
만약 p_H=0.5 일 경우, 두번 모두 앞면이 나올 확률은 0.25이다:
P(HH | p_H=0.5)=0.25
이를 통해, 관측결과가 HH 라면, p_H=0.5 의 가능도는 0.25라고 말할 수 있다.
L(p_H=0.5| HH)=P(HH | p_H=0.5)=0.25
그러나 이것은 관측결과가 HH라면, p_H=0.5 의 확률은 0.25 이라고 말하는 것과 같지 않다.
이를 위해서는 베이지안 추론의 개념이 필요하다. 특히, 베이 즈 정리 (Bayes 's theorem)는 사후 확률 (밀도)이 가능도 (likelihood)과 사전 확률에 비례함을 말한다.
개요
확률은 관측값(x)를 입력해서 얻은 값입니다. x가 발생할 가능성을 표시한 것이 확률입니다. Pr(x)로 표시합니다. 그런데 위에서 표시된 가능도의 공식에서 가능도는 Pr(X=x|θ) 로 되어있습니다. Pr, X, θ라는 조건이 더/다르게 들어있습니다. 즉, 확률과는 다르게 θ까지 추가로 고려한 확률을 가능도라 부릅니다. 여기서 θ는 모수의 확률분포를 계산하는 데 사용되는 변수 입니다. 아주 간단히 말하면 가능도는 관측치(x)와 확률함수의 변수(θ)를 가지고 계산된 값입니다. 확률함수는 확률밀도함수 또는 확률질량함수를 말합니다. 연속 확률 분포에서는 확률계산을 위해 확률밀도함수(PDF)를 쓰고 이산 확률 분포에서는 확률질량함수(PMF)를 씁니다. 아래에서 예를 들어보겠습니다.
Example
이산 확률분포(이항분포) : 동전 던지기 예시
이항분포이기 때문에 확률질량함수를 사용합니다.
이항 분포 확률질량함수(PMF) 는 아래와 같습니다.

우리는 이미 동전을 던질때 앞면(H)/뒷면이 나올 확률이 0.5라는 것을 알고 있습니다. 즉, p가 0.5인 것을 알고 있습니다. 그래서 앞면이 두번 나올 확률을 계산하면 다음과 같습니다.
P(H) = 0.5라고 할때, P(HH) = P(H) * P(H) = 0.5 * 0.5 = 0.25
그럼 가능도는 얼마일까요? 공식은 L(θ|x) 입니다. 확률질량함수는 위에서 정의된 것을 이용하면되고 그 안의 (θ)변수 p 를 0.5로 입력해서 계산하면 아래와 같습니다.
L(θ|x) = Pr(X=x|θ) = Pr(X=HH|0.5) = (2, 2)* 0.5^2 * (1-0.5)^(2-2) = 0.5 * 0.5 = 0.25
확률 값과 가능도 값이 같네요. 이말을 풀어서 설명하면
(확률로 설명) 동전을 던져서 앞면이 나올 확률이 0.5인 동전을 두번 던져서 앞면이 두번 나올 확률은 0.25이고,
(가능도로 설명) 동전을 던져서 앞면이 나올 확률(θ)이 0.5인 경우 동전을 두번 던져서 앞면이 두번 나올 가능성이 0.25이다. 다른 점은 확률(θ)를 입력 변수로 사용한다는 것입니다. 그럼 앞면이 나올 확률값을 0.4를 바꾸어서 계산해 보겠습니다.
(n, k)p^k (1-p)^(n-k)
= 0.4^2 = 0.16
이 결과는 앞면이 나올 확률값이 0.4인 동전을 두번 던져서 앞면이 두번 나올 가능성은 0.16이다.라는 의미입니다. 이번에는 0.8로 바꾸어서 계산해 보겠습니다.
0.8^2 = 0.64
이 결과는 앞서 설명한 내용과 유사합니다. 앞면이 나올 확률값이 0.8인 동전을 두번 던져서 앞면이 두번 나올 가능성은 0.64 이다. 라는 말입니다. 생각해보시지요. 동전이 두 종류가 있습니다. 하나는 앞면이 나올 확률이 0.4이고 다른 하나는 앞면이 나올 확률이 0.8입니다. 둘중에 어떤 동전을 선택했는지는 모르지만 둘중 하나의 동전을 선택해서 던진다고 가정할 때 두번 모두 앞면이 나올 가능성을 계산할 수 있습니다. 0.4 동전을 던지면 가능성이 0.16이고 0.8인 동전을 두번 던지면 0.64 가능성이 있습니다. 이처럼 동전의 앞면 확률(사전확률)이 얼마인지 모를때 가능도를 계산해서 어느 동전일 가능성이 높은 지(사전확률을)를 계산해서 찾을 수 있습니다. 이경우 가장 가능성이 높은 동전의 앞면확률을 찾으면 당연히 1인 동전이 되겠지요.(왜냐하면 1일때 가능도가 1(100%)가 되니까요.) 이처럼 최대 가능도를 찾을 수 있는데 이를 최대가능도법(MLE)라고 합니다.
정규분포 : 키 측정 예시
이번에는 정규분포의 설명을 위해 한사람의 키를 가지고 설명해 보겠습니다.
정규분포함수 확률밀도함수(PDF)

= f(x) = 1 / σ√2π * e^(-1/2 * ((x-u)/σ)^2)
정규분포의 확률을 계산하려면 확률밀도 함수를 사용합니다. 이를 이용하려면 확률밀도함수 공식에 있는 모평균(u), 즉 실제 키를 알아야하 합니다. 다른 말로 설명하면 실제 키를 알야야 확률을 구할 수 있습니다. 이 말은 실제키가 170일때 측정값 169가 나올 확률이 얼마인지를 계산할 수 있다는 말입니다. 표준편차(σ)는 1이라고 가정하고 위의 공식에 대입해 보겠습니다.
f(x) = 1 / σ√2π * e^(-1/2 * ((x-u)/σ)^2)
= 1 / √2π * e^(-1/2 * (169-170)^2)
= 1 / √2π * e^(-1/2 * 1)
= 1 / 2.5066 * e^(-1/2)
= 1 / 2.5066 * 0.6065
= 0.2419
정규분포의 가능도를 계산해보겠습니다.
똑 같은 가정, 즉, 실제 키가 170이고 표준편차가 1이라면 확률값과 가능도는 일치합니다. 그러나 실제 키와 표준편차를 모를 때는 확률을 구할 수 없습니다. 그대신 가능도를 구합니다. 왜냐하면 가능도는 169가 평균이 170일때 나올 가능도를 알려줍니다. 그럼 다시 평균이 169일때 나올 가능도를 구해보겠습니다.
f(x) = 1 / σ√2π * e^(-1/2 * ((x-u)/σ)^2)
= 1 / √2π * e^(-1/2 * (169-169)^2)
= 1 / √2π * e^(-1/2 * 0)
= 1 / √2π * e^(0)
= 1 / 2.5066 * 1
= 0.3989 * 1
= 0.3989
키 169는 평균이 170인 집단에서 뽑힐 가능도가 0.2419이고 평균이 169인 집단에서 뽈힐 가능도가 0.3989 로 169인 집단의 가능도가 더 큽니다. 상식적으로도 이해가 됩니다. 평균이 제일 많이 발생하는 숫자일 가능성이 높으니까 평균이 170일때 보다는 (같은 값인) 169일때 더 뽑힐 가능성이 높습니다.
이해가 되시나요?! ^^
Summary
지금까지 가능도에 대한 정의와 실제 예를 들어 그 값을 계산해 보았습니다.
다시 정리하면 가능도는 관측치(x)와 확률함수의 변수(θ)를 가지고 계산된 값입니다. 이 계산 방법은 분포마다 다릅니다.
정규분포의 확률을 구하려면 실제 집단의 평균(모평균)을 알아야 하는데 대부분이 모르는 경우이기 때문에 계산할 수 없고, 이런 변수들을 추정값으로 이용하여 가능도를 구할 수 있습니다.
의문이 듭니다. 가능도는 가정한 변수를 통해 얻은 값이라 정확하지도 않을 것 같은데 이러한 가능도는 어디에 어떻게 쓸수 있을까요?
위에서 잠깐 언급한 것처럼 최대 가능도를 갖는 변수(theta)를 구하는데 사용될 수 있습니다. 관측된 여러 값들과 추정되는 모수를 가지고 가능도를 구할 수 있는데 추정값들을 바꾸어가면서 가장 가능도가 높은 모수를 구할 수 있습니다. 이렇게 되면 모수(모평균, 모분산)등을 몰라도 가능도가 가장 놓은 모수를 구할 수 있습니다. 즉, 모르고 있던 실제 값들을 가장 높은 가능도로 알 수 있게 됩니다. 이러한 방법이 최대가능도법(MLE)입니다.
다음에는 최대가능도법(MLE)과 그 활용방법을 알아보겠습니다.
https://bigdatamaster.tistory.com/158
최대가능도방법 MLE: Maximum Likelihood Estimation
최대가능도방법 MLE: Maximum Likelihood Estimation 정의 최대가능도법 MLE에 대해서 알아보겠습니다. 아래는 위키에서 정의된 내용입니다. 최대가능도방법 (最大可能度方法, 영어: maximum likelihood me.
bigdatamaster.tistory.com
추가: 아래에 있는 위키의 예제를 보시면 이해가 되실껍니다. (설명이 조금 딱딱하긴 하네요) ^^
예 2
동전을 던져서, 앞면(H)이 나오는 확률을p_H 라고 하자. 이때, 앞면이 두번 나오는 확률은 p_H^2이다.
만약 p_H=0.5 일 경우, 두번 모두 앞면이 나올 확률은 0.25이다:
P(HH | p_H=0.5)=0.25
이를 통해, 관측결과가 HH 라면, p_H=0.5 의 가능도는 0.25라고 말할 수 있다.
L(p_H=0.5| HH)=P(HH | p_H=0.5)=0.25
그러나 이것은 관측결과가 HH라면, p_H=0.5 의 확률은 0.25 이라고 말하는 것과 같지 않다.
이를 위해서는 베이지안 추론의 개념이 필요하다. 특히, 베이 즈 정리 (Bayes 's theorem)는 사후 확률 (밀도)이 가능도 (likelihood)과 사전 확률에 비례함을 말한다.
'인공지능-기계학습 > 통계_모델_알고리즘' 카테고리의 다른 글
| [차원축소/시각화 방법] TSNE - Python 에서 T-SNE를 이용하는 방법 (0) | 2022.07.25 |
|---|---|
| 퍼셉트론 Perceptron (0) | 2022.03.13 |
| 최대가능도방법 MLE: Maximum Likelihood Estimation (0) | 2022.03.12 |
| 확률 밀도 함수 PDF (Probability Density Function) (0) | 2022.03.10 |
| 다항분포 나이브 베이지안 분류-이해하기 쉽게 (0) | 2021.07.11 |